




Large language models (LLMs) have revolutionized artificial intelligence, showing prowess in handling complex reasoning and mathematical tasks. However, these models face fundamental challenges in basic numerical understanding, an area often essential for more advanced mathematical reasoning. Researchers are increasingly exploring how LLMs manage numerical concepts like decimals, fractions, and scientific notation. The potential applications of robust numerical understanding span fields like finance, physics, and everyday reasoning, underscoring the significance of refining LLMs’ numerical skills.
The core challenge lies in LLMs’ tendency to produce numerical errors despite their impressive capabilities. For instance, they may incorrectly compare 9.11 as greater than 9.9 or fail simple arithmetic, even though these errors might seem trivial. Such issues compromise models’ reliability in real-world applications. This problem is rooted in a need for a more comprehensive focus on the numerical understanding and processing ability (NUPA) of these models, which is essential not only for arithmetic but also as a building block for broader reasoning abilities. Therefore, a method for systematically evaluating and enhancing NUPA in LLMs is needed.

While current evaluations of LLMs examine their reasoning and problem-solving abilities, most need to isolate and measure numerical understanding specifically. Existing benchmarks, like GSM8k, often mix numerical tasks within broader reasoning assessments, making it difficult to gauge how well LLMs handle numbers independently. Moreover, these tests frequently use simplified arithmetic, such as integer-based problems, which are far removed from real-world complexity involving various numerical formats. With targeted benchmarks, researchers can accurately identify weaknesses or refine LLMs for practical numerical tasks that require precision and contextual understanding.
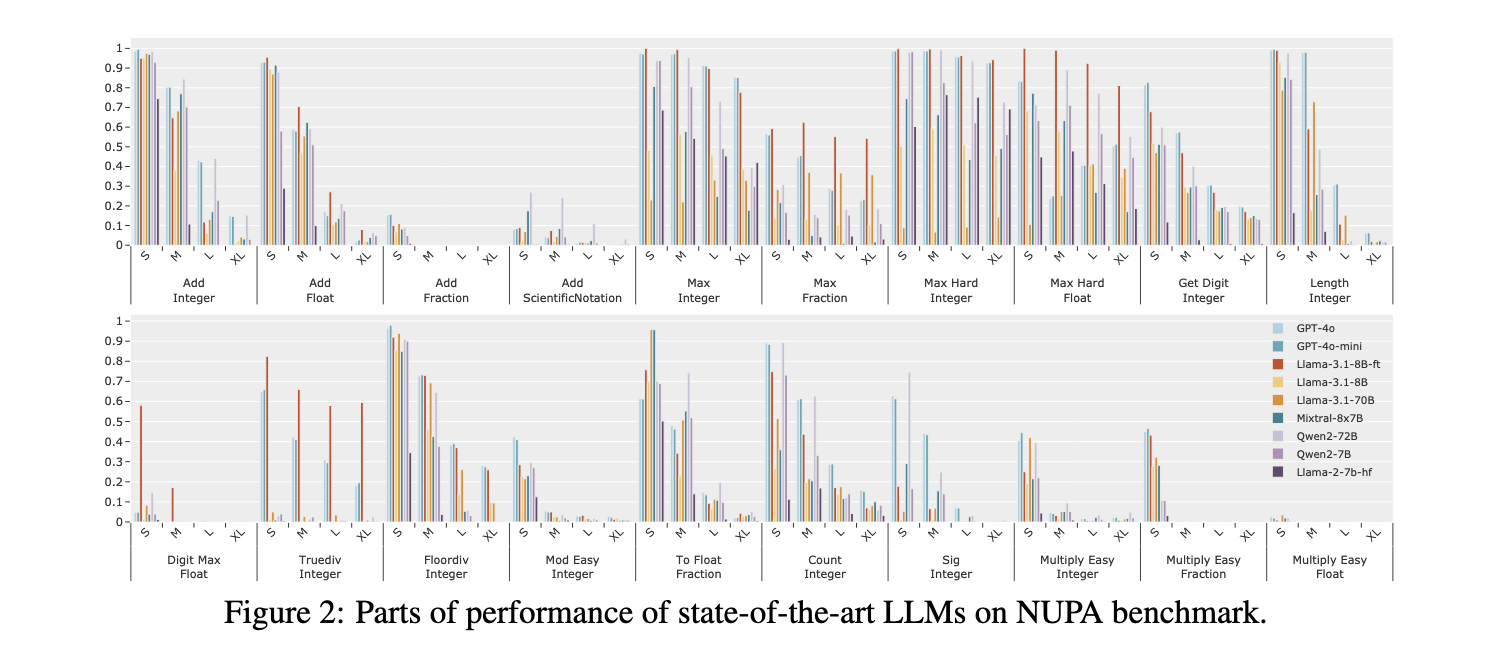
Researchers at Peking University introduced a specialized benchmark for measuring NUPA in LLMs. This benchmark assesses four common numerical formats—integers, fractions, floating-point numbers, and scientific notation—across 17 distinct task categories. By doing so, the benchmark aims to cover nearly all real-world numerical understanding scenarios. The benchmark does not rely on external tools, thereby evaluating LLMs’ self-contained NUPA. This work by Peking University researchers contributes to the field by establishing a foundation for enhancing LLMs’ performance on a wide range of numerical tasks.
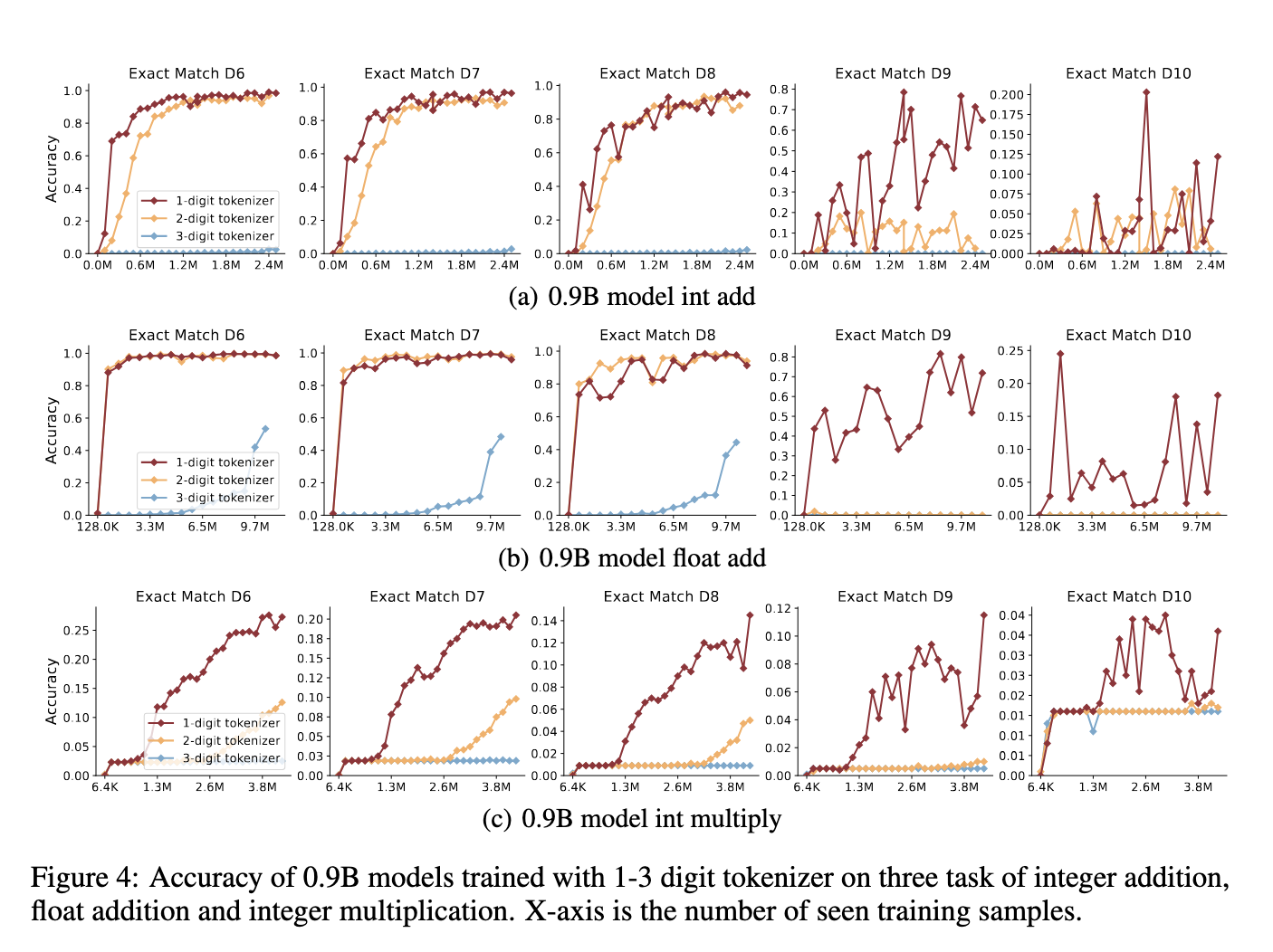
To comprehensively evaluate LLMs’ NUPA, the researchers employed several pre-training techniques to measure task performance and identify weaknesses—techniques included using special tokenizers and positional encoding (PE) to address numerical complexity. For instance, researchers tested integer, fraction, and floating-point number tasks using one-digit tokenizers, multi-digit tokenizers, and random tokenization techniques, finding that simpler tokenizers often yielded better accuracy. The study also introduced length regularization methods to evaluate whether these techniques could help models process longer numbers without accuracy degradation. By implementing these modifications in small-scale LLMs and testing on complex task categories, researchers assessed how various numerical representations impact the ability of LLMs to align and process numbers effectively.
The research yielded noteworthy results, revealing both strengths and significant limitations of current LLMs in handling numerical tasks. Models like GPT-4o performed well on simpler tasks involving short integers and basic arithmetic, achieving close to 100% accuracy in the shortest ranges. However, performance declined sharply as complexity increased—such as tasks involving scientific notation or more extended numerical sequences. For example, GPT-4o’s accuracy dropped from nearly 100% in simple integer addition to around 15% in more complex tasks requiring longer sequences. Furthermore, experiments showed that even common tasks like integer addition suffered from drastic accuracy reductions as the number of digits increased, from 80% in medium-length ranges to a mere 5% in longer ranges. Qwen2 and Llama-3.1 models, struggling with fractions and digit-specific tasks, displayed similar limitations.
Further, length remains a crucial challenge. For tasks involving integers and fractions, accuracy diminished as input length grew, with models frequently needing to maintain correct length alignment in their responses. Models’ limited ability to handle longer number strings impacted their digit accuracy and overall result length, suggesting that sequence length disrupts both per-digit and total length accuracy. Further analysis indicated that the LLMs’ understanding of digits could have been more consistent, leading to errors in tasks like retrieving or comparing specific digits from large numbers.
Through this research, Peking University’s team highlighted the limitations in LLMs’ foundational numerical abilities, pointing out that existing methods for enhancing NUPA must be revised to address these challenges fully. Their findings suggest that while tokenizer adjustments and positional encoding offer minor improvements, revolutionary changes may be necessary to meet the demands of complex numerical reasoning tasks. The work advocates for further development in training models focusing on numerical understanding, thereby laying the groundwork for creating robust and reliable NUPA capabilities suitable for real-world applications.
In conclusion, the research underscores a clear need for enhanced methodologies and training data to improve numerical reasoning and processing in LLMs. The Peking University team’s work addresses the gap between current LLMs’ reasoning capabilities and their practical numerical reliability, promoting future advancements in AI research and its real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post Researchers at Peking University Introduce A New AI Benchmark for Evaluating Numerical Understanding and Processing in Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ