




Neural networks remain a beguiling enigma to this day. On the one hand, they are responsible for automating daunting tasks across fields such as image vision, natural language comprehension, and text generation; yet, on the other hand, their underlying behaviors and decision-making processes remain elusive. Neural networks many times exhibit counterintuitive and abnormal behavior, like non-monotonic generalization performance, which reinstates doubts about their caliber. Even XGBoost and Random Forests outperform neural networks in structured data. Furthermore, neural nets often behave like linear models—this invokes great confusion, given that they are renowned for their ability to model complex nonlinearities. These issues have motivated researchers to decode neural networks.
Researchers at the University of Cambridge presented a simple model to provide empirical insights into neural networks. This work follows a hybrid approach to applying theoretical research principles to simple yet accurate models of neural networks for empirical investigation. Inspired by the work of Neural Tangent Kernels, the authors consider a model that uses first-order approximations for functional updates made during training. Moreover, in this definition, the model increments by telescoping out approximations to individual updates made during training to replicate the behavior of fully trained practical networks. The whole setup to conduct empirical investigations could be articulated as a pedagogical lens to showcase how neural networks sometimes generalize seemingly unpredictably. The research also proposes methods to construct and extract metrics for predicting and understanding this abnormal behavior.
The authors present three case studies in this paper for empirical investigation. Firstly, the proposed telescopic model extends an existing metric for measuring model complexity to neural networks. The purpose of this incorporation was to understand the overfitting curves and generalizing behavior of networks, especially on new data when the model underperformed. Their findings included the phenomenon of double descent and grokking linked to changes in the complexity of the model during training and testing. Double descent basically explains the non-monotonic performance of the telescopic model when its test performance first worsened (normal overfitting) but then improved upon increasing model complexity. In grokking, even after achieving perfect performance on the training data, a model may continue to improve its performance on the test data significantly after a long period. The telescopic model quantifies learning complexity, double descent, and grokking during training and establishes the causation of these effects to be the divergence between training and test complexity.
The second case study explains the underperformance of neural networks relative to XGBoost on tabular data. Neural Networks struggle with tabular data, particularly those with irregularities, despite their remarkable versatility. Although both models exhibit similar optimization behaviors, XGBoost wins the race by better handling feature irregularities and sparsity. In the study, the telescopic model and XGBoost used kernels, but it was established that the tangent kernel of neural nets was unbounded, which meant every point could be used differently, while XGBoost kernels behaved more predictably when exposed to test data.
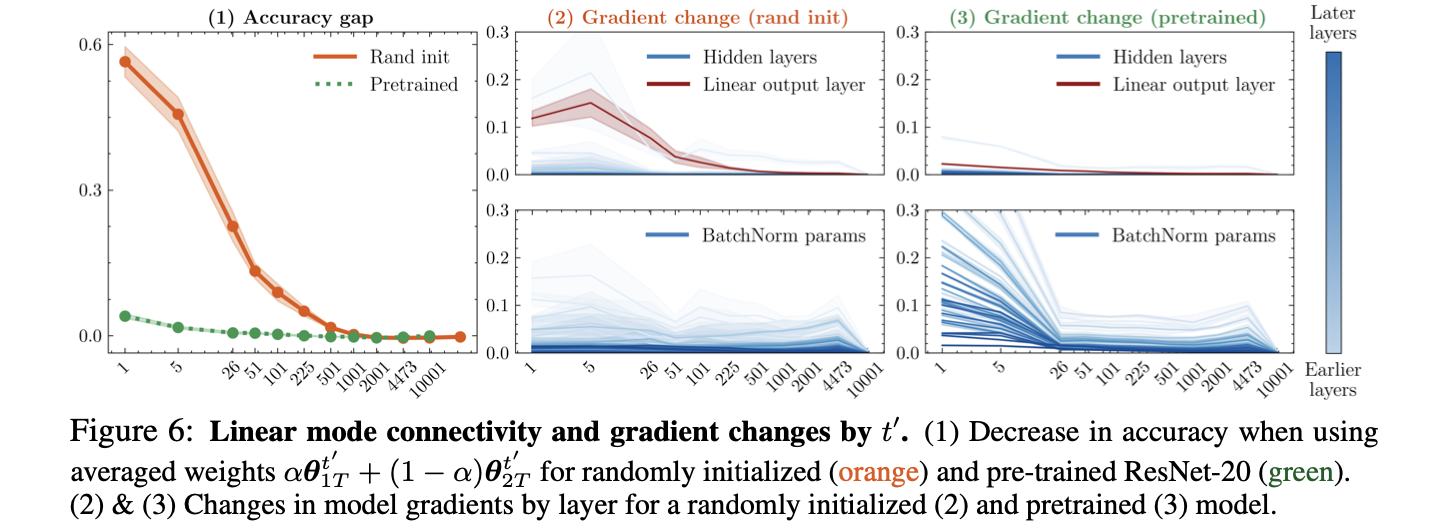
The last case discussed gradient stabilization and weight averaging. The model revealed that as training progresses, gradient updates become more aligned, leading to smoother loss surfaces. They showed how gradient stabilization during training contributes to linear mode connectivity and weight averaging, which has become very successful.
The proposed telescopic model for neural network learning helped in understanding several perplexing phenomena in deep learning through empirical investigations. This work would instigate more efforts to understand the mystery of neural nets both empirically and theoretically.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post Researchers at Cambridge Provide Empirical Insights into Deep Learning through the Pedagogical Lens of Telescopic Model that Uses First-Order Approximations appeared first on MarkTechPost.
Source: Read MoreÂ
