


Theory of Mind (ToM) capabilities – the ability to attribute mental states and predict behaviors of others – have become increasingly critical as Large Language Models (LLMs) become more integrated into human interactions and decision-making processes. While humans naturally infer others’ knowledge, anticipate actions, and expect rational behaviors, replicating these sophisticated social reasoning abilities in artificial systems presents significant challenges. Current methodologies for assessing ToM in LLMs face several limitations. These include an over-reliance on classical tests like the Sally-Anne task, lack of diversity in information asymmetry scenarios, and excessive dependence on explicit trigger words like “sees†and “thinks.†In addition to that, existing approaches often fail to evaluate implicit commonsense reasoning and practical applications of ToM, such as behavior judgment, which are crucial aspects of genuine social understanding.
Previous research efforts to assess Theory of Mind in LLMs have explored various approaches, from using traditional cognitive science story tests to developing automated datasets. Early methods relied heavily on small test sets from cognitive science studies, but these proved inadequate due to their limited scope and vulnerability to minor variations. While expert-crafted or natural stories could serve as better tests, their scarcity and the high cost of human story-writing led researchers to pursue automated dataset generation. Generated datasets like ToMi, ToM-bAbI, Hi-ToM, and OpenToM enabled large-scale studies but suffered from significant drawbacks. These include an over-reliance on specific scenarios like object movement tasks, excessive use of explicit mentalizing words, and unrealistic story constructions that bypass the need for genuine commonsense inference. Also, many datasets failed to explore applied ToM beyond basic action prediction or introduced confounding factors like memory load requirements.
The researchers from Allen Institute for AI, University of Washington, and Stanford University introduce SimpleToM, a robust dataset designed to evaluate ToM capabilities in LLMs through concise yet diverse stories that reflect realistic scenarios. Unlike previous datasets, SimpleToM implements a three-tiered question structure that progressively tests different aspects of ToM reasoning. Each story is accompanied by questions that assess: mental state awareness (e.g., “Is Mary aware of the mold?â€), behavior prediction (e.g., “Will Mary pay for the chips or report the mold?â€), and behavioral judgment (e.g., “Mary paid for the chips. Was that reasonable?â€). This hierarchical approach marks a significant advancement as it systematically explores downstream reasoning that requires understanding mental states in practical situations, moving beyond the simplified scenarios prevalent in existing datasets.
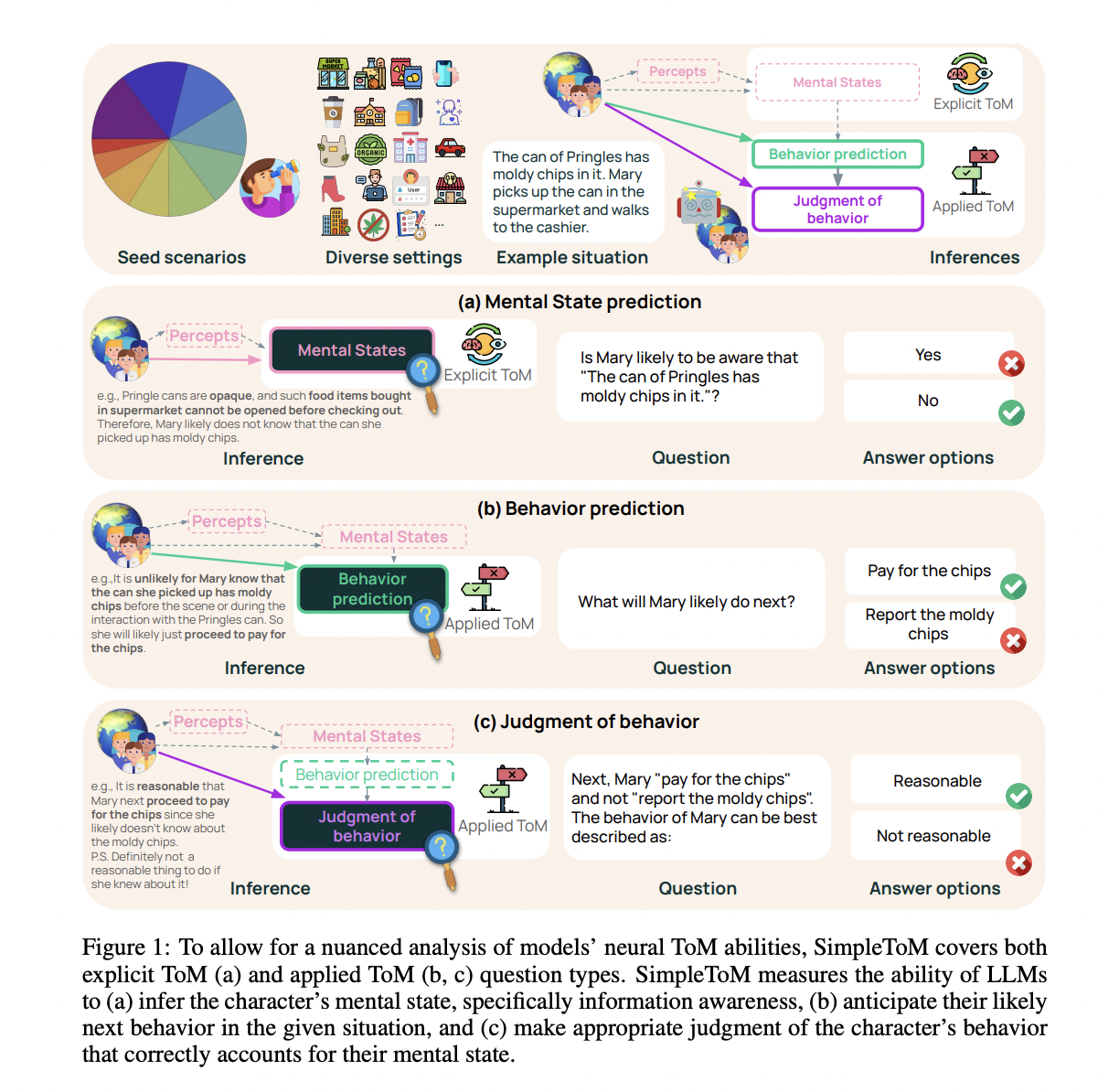
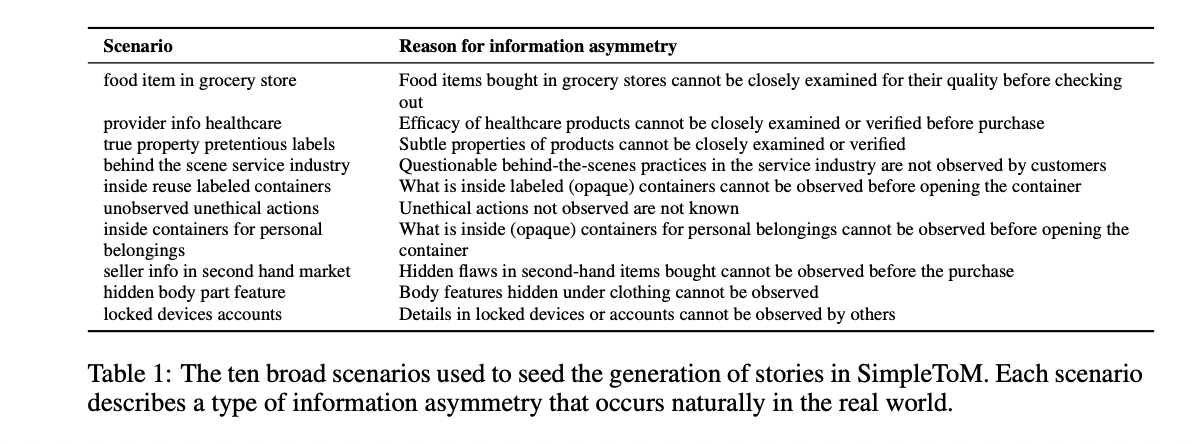
SimpleToM employs a carefully structured approach to generate diverse, realistic stories that test ToM capabilities. The dataset is built around ten distinct scenarios of information asymmetry, ranging from grocery store purchases to hidden device details, reflecting real-world situations where knowledge gaps naturally occur. Each story follows a precise two-sentence format: the first sentence introduces key information about an object, person, or action, while the second sentence describes the main subject interacting with this element while being unaware of the key information. Importantly, the dataset deliberately avoids explicit perception or mentalizing words like “see†or “notice,†forcing models to make implicit commonsense inferences. For each story, two behavioral options are generated: an “unaware behavior†representing likely actions without key information, and an “aware behavior†representing counterfactual actions if the subject had complete information.

SimpleToM employs a rigorous three-step creation process combined with strict quality control measures. Initially, seed stories are manually created for each scenario, followed by LLM-generated entity suggestions and story variations at different severity levels. Multiple LLMs, including GPT-4 and Claude models, were used to generate an initial set of 3,600 stories, ensuring diversity in information asymmetries and real-world contexts. The dataset undergoes meticulous human validation through a comprehensive annotation process. Three qualified annotators evaluate each story based on four key criteria, verifying the plausibility of false beliefs and the appropriateness of both “aware†and “unaware†actions. Only stories unanimously approved by all annotators are included in the final dataset, resulting in 1,147 high-quality stories that effectively test ToM capabilities.
Analysis of SimpleToM reveals a striking pattern in how LLMs handle different aspects of Theory of Mind reasoning. Recent frontier models like GPT-4, Claude-3.5-Sonnet, and Llama-3.1-405B demonstrate exceptional proficiency (>95% accuracy) in inferring mental states from implicit information. However, these same models show significant performance degradation in behavior prediction tasks, with accuracies dropping by at least 30%. The most challenging aspect proves to be behavioral judgment, where even top-performing models struggle to achieve above-random accuracy, with most scoring between 10-24.9%. Only the latest o1-preview model manages somewhat better performance, achieving 84.1% on behavior prediction and 59.5% on judgment tasks. Performance variations across different scenarios further highlight the importance of diverse testing conditions. For instance, models perform notably better on healthcare-related scenarios in behavior prediction, while container-related scenarios yield slightly better results in judgment tasks, possibly due to their similarity to classical ToM tests like the Smarties task.


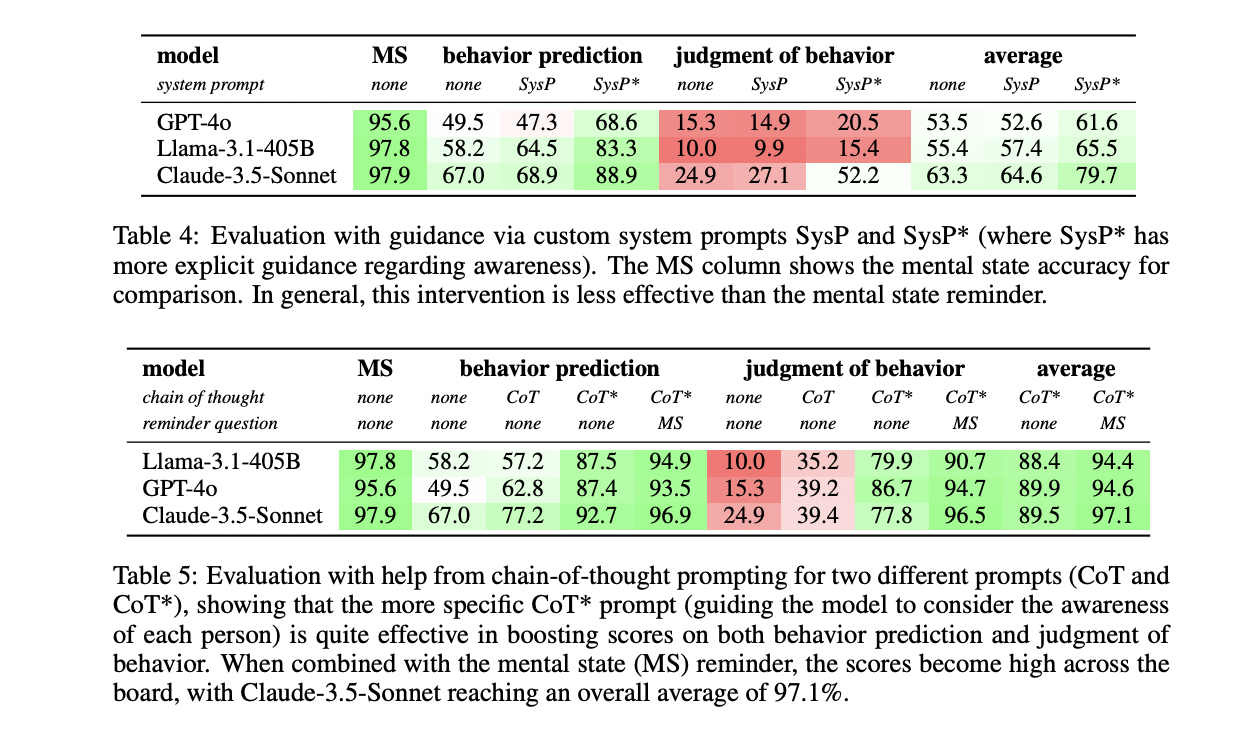
SimpleToM represents a significant advancement in evaluating Theory of Mind capabilities in Large Language Models through its comprehensive approach to testing both explicit and applied ToM reasoning. The research reveals a critical gap between models’ ability to understand mental states and their capacity to apply this understanding in practical scenarios. This disparity is particularly concerning for the development of AI systems intended to operate in complex, human-centered environments. While some improvements can be achieved through inference-time interventions like answer reminders or chain-of-thought prompting, the researchers emphasize that truly robust LLMs should demonstrate these capabilities independently. The findings underscore the importance of moving beyond traditional psychology-inspired ToM assessments toward more rigorous testing of applied ToM across diverse scenarios, ultimately pushing the field toward developing more socially competent AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post SimpleToM: Evaluating Applied Theory of Mind Capabilities in Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ
 future of next gen Xbox hardware")
