




The advancement of artificial intelligence hinges on the availability and quality of training data, particularly as multimodal foundation models grow in prominence. These models rely on diverse datasets spanning text, speech, and video to enable language processing, speech recognition, and video content generation tasks. However, the lack of transparency regarding dataset origins and attributes creates significant barriers. Using training data that is geographically and linguistically skewed, inconsistently licensed, or poorly documented introduces ethical, legal, and technical challenges. Understanding the gaps in data provenance is essential for advancing responsible and inclusive AI technologies.
AI systems face a critical issue in dataset representation and traceability, which limits the development of unbiased and legally sound technologies. Current datasets often rely heavily on a few web-based or synthetically generated sources. These include platforms like YouTube, which accounts for a significant share of speech and video datasets, and Wikipedia, which dominates text data. This dependency results in datasets failing to represent underrepresented languages and regions adequately. In addition, the unclear licensing practices of many datasets create legal ambiguities, as more than 80% of widely used datasets carry some form of undocumented or implicit restrictions despite only 33% being explicitly licensed for non-commercial use.
Attempts to address these challenges have traditionally focused on narrow aspects of data curation, such as removing harmful content or mitigating bias in text datasets. However, such efforts are typically limited to single modalities and lack a comprehensive framework to evaluate datasets across modalities like speech and video. Platforms hosting these datasets, such as HuggingFace or OpenSLR, often lack the mechanisms to ensure metadata accuracy or enforce consistent documentation practices. This fragmented approach underscores the urgent need for a systematic audit of multimodal datasets that holistically considers their sourcing, licensing, and representation.
To close this gap, researchers from the Data Provenance Initiative conducted the largest longitudinal audit of multimodal datasets, examining nearly 4,000 public datasets created between 1990 and 2024. The audit spanned 659 organizations from 67 countries, covering 608 languages and nearly 1.9 million hours of speech and video data. This extensive analysis revealed that web-crawled and social media platforms now account for most training data, with synthetic sources also rapidly growing. The study highlighted that while only 25% of text datasets have explicitly restrictive licenses, nearly all content sourced from platforms like YouTube or OpenAI carries implicit non-commercial constraints, raising questions about legal compliance and ethical use.
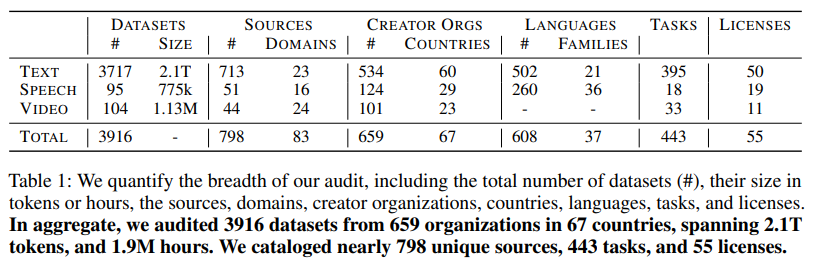
The researchers applied a meticulous methodology to annotate datasets, tracing their lineage back to sources. This process uncovered significant inconsistencies in how data is licensed and documented. For instance, while 96% of text datasets include commercial licenses, over 80% of their source materials impose restrictions that are not carried forward in the dataset’s documentation. Similarly, video datasets highly depended on proprietary or restricted platforms, with 71% of video data originating from YouTube alone. Such findings underscore the challenges practitioners face in accessing data responsibly, particularly when datasets are repackaged or re-licensed without preserving their original terms.
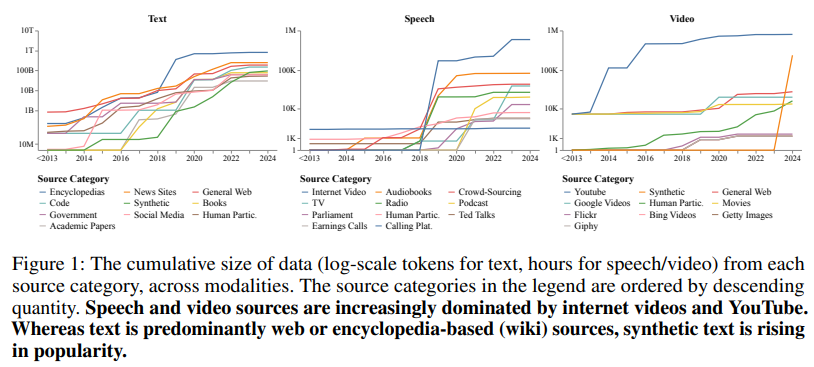
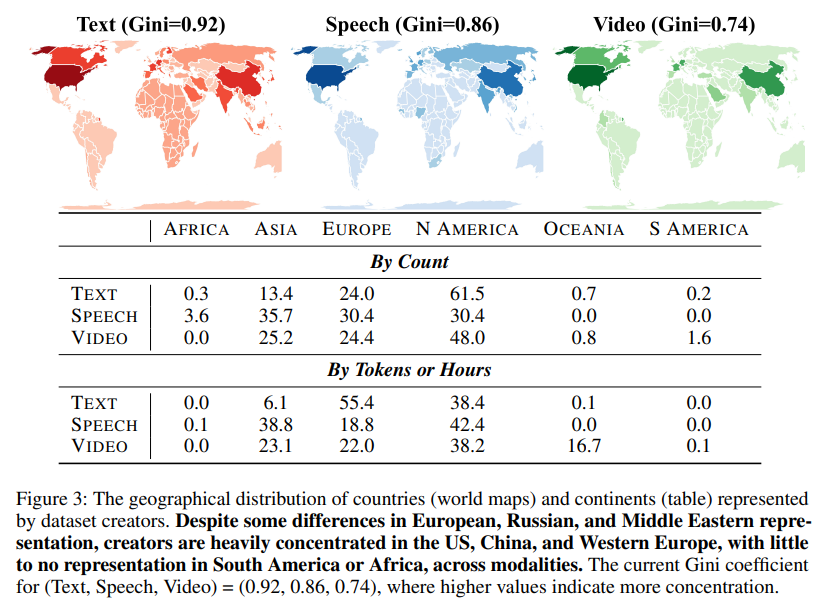
Notable findings from the audit include the dominance of web-sourced data, particularly for speech and video. YouTube emerged as the most significant source, contributing nearly 1 million hours to each speech and video content, surpassing other sources like audiobooks or movies. Synthetic datasets, while still a smaller portion of overall data, have grown rapidly, with models like GPT-4 contributing significantly. The audit also revealed stark geographical imbalances. North American and European organizations accounted for 93% of text data, 61% of speech data, and 60% of video data. In comparison, regions like Africa and South America collectively represented less than 0.2% across all modalities.
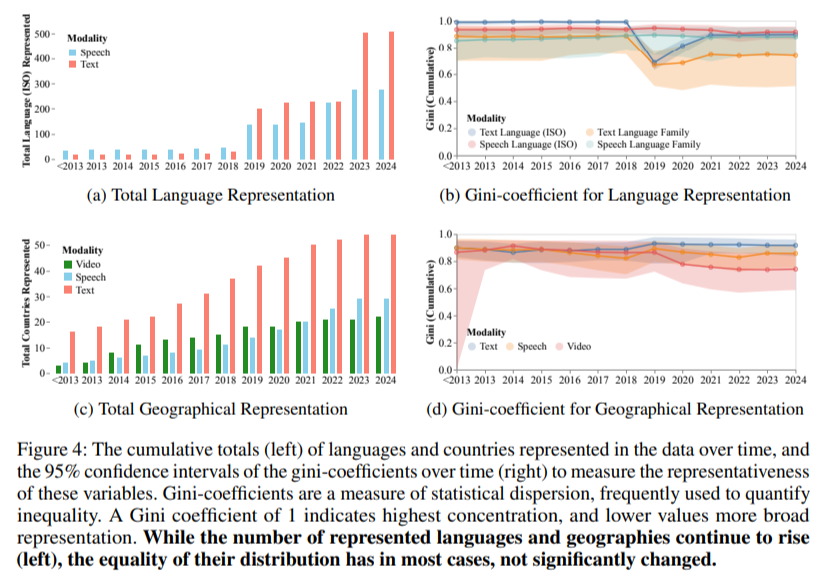
Geographical and linguistic representation remains a persistent challenge despite nominal increases in diversity. Over the past decade, the number of languages represented in training datasets has grown to over 600, yet measures of equality in representation have shown no significant improvement. The Gini coefficient, which measures inequality, remains above 0.7 for geographical distribution and above 0.8 for language representation in text datasets, highlighting the disproportionate concentration of contributions from Western countries. For speech datasets, while representation from Asian countries like China and India has improved, African and South American organizations continue to lag far behind.
The research provides several critical takeaways, offering valuable insights for developers and policymakers:
- Over 70% of speech and video datasets are derived from web platforms like YouTube, while synthetic sources are becoming increasingly popular, accounting for nearly 10% of all text data tokens.
- While only 33% of datasets are explicitly non-commercial, over 80% of source content is restricted. This mismatch complicates legal compliance and ethical use.
- North American and European organizations dominate dataset creation, with African and South American contributions at less than 0.2%. Linguistic diversity has grown nominally but remains concentrated in many dominant languages.
- GPT-4, ChatGPT, and other models have significantly contributed to the rise of synthetic datasets, which now represent a growing share of training data, particularly for creative and generative tasks.
- The lack of transparency and persistent Western-centric biases call for more rigorous audits and equitable practices in dataset curation.
In conclusion, this comprehensive audit sheds light on the growing reliance on web-crawled and synthetic data, the persistent inequalities in representation, and the complexities of licensing in multimodal datasets. By identifying these challenges, the researchers provide a roadmap for creating more transparent, equitable, and responsible AI systems. Their work underscores the need for continued vigilance and measures to ensure that AI serves diverse communities fairly and effectively. This study is a call to action for practitioners, policymakers, and researchers to address the structural inequities in the AI data ecosystem and prioritize transparency in data provenance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post This AI Paper by The Data Provenance Initiative Team Highlights Challenges in Multimodal Dataset Provenance, Licensing, Representation, and Transparency for Responsible Development appeared first on MarkTechPost.
Source: Read MoreÂ
