




Large language models (LLMs) with long-context processing capabilities have revolutionized technological applications across multiple domains. Recent advancements have enabled sophisticated use cases including repository-level coding assistance, multi-document analysis, and autonomous agent development. These models demonstrate remarkable potential in handling extensive contextual information, requiring advanced mechanisms to retrieve and integrate dispersed details effectively. However, the current landscape reveals significant challenges in maintaining consistent performance across complex reasoning tasks. While LLMs have achieved near-perfect accuracy in needle-in-a-haystack scenarios, substantial performance limitations persist when confronting more nuanced long-context reasoning challenges. This variability highlights the critical need for innovative approaches to enhance contextual understanding and reasoning capabilities in artificial intelligence systems.
Research in long-context language modeling has emerged as a critical frontier in artificial intelligence, exploring innovative approaches to enhance large language models’ contextual processing capabilities. Two primary research trajectories have gained prominence: model-centered and data-centric methodologies. Model-centered strategies involve targeted modifications to existing architectures, including subtle adjustments to position embeddings and attention mechanisms. Researchers have also proposed unique architectural designs aimed at improving computational efficiency and contextual comprehension. Simultaneously, data-centric approaches focus on sophisticated data engineering techniques, such as continued pretraining on extended sequences and utilizing expert models or human annotations for refined training data. These multifaceted research efforts collectively aim to push the boundaries of language models’ contextual understanding and reasoning capabilities, addressing fundamental challenges in artificial intelligence systems.
Researchers from The Chinese University of Hong Kong, Peking University, Tsinghua University, and Tencent introduce SEALONG, a robust self-improving methodology designed to enhance large language models’ reasoning capabilities in long-context scenarios. By sampling multiple reasoning trajectories and employing Minimum Bayes Risk (MBR) scoring, the method prioritizes outputs demonstrating higher consistency across generated responses. This approach addresses the critical challenge of hallucination in language models by identifying and prioritizing reasoning paths that align more closely with collective model outputs. The methodology offers two primary optimization strategies: supervised fine-tuning using high-scoring outputs and preference optimization involving both high and low-scoring trajectories. Experimental evaluations across leading language models demonstrate significant performance improvements, with notable increases in long-context reasoning capabilities without relying on external human or expert model annotations.
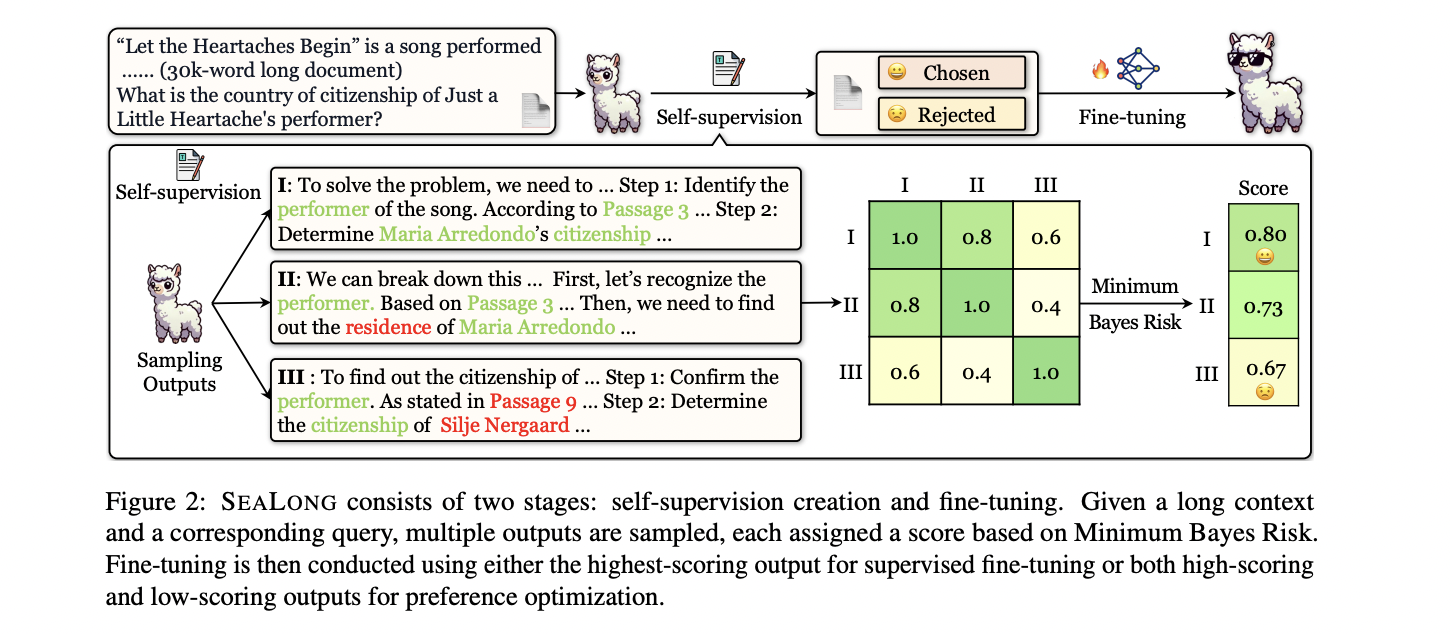
SEALONG introduces an innovative two-stage methodology for enhancing long-context reasoning in large language models. The approach centers on self-supervision and model fine-tuning, utilizing a robust evaluation technique based on MBR decoding. By generating multiple reasoning trajectories for each input, the method assesses output quality through semantic consistency and embedding similarity. This approach enables the model to identify and prioritize more reliable reasoning paths by comparing different generated outputs. The technique employs a Monte Carlo method to score each trajectory, effectively distinguishing between potentially hallucinated and more accurate responses. Crucially, SEALONG demonstrates significant performance improvements without relying on external human annotations or expert model interventions.
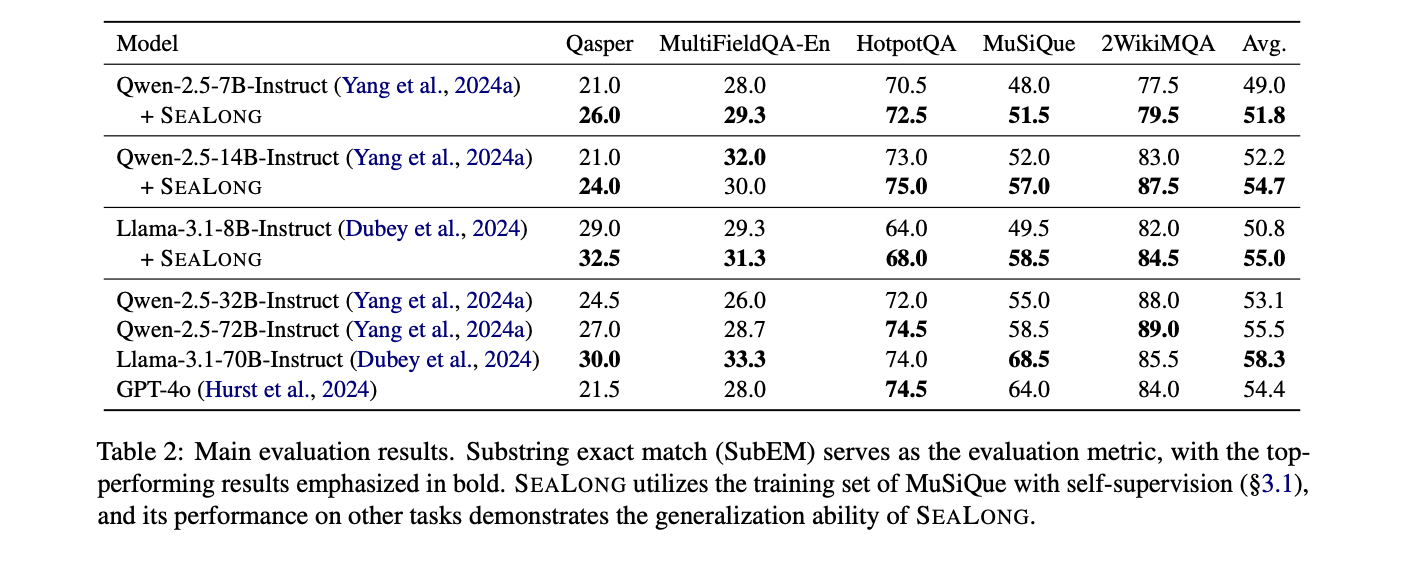
This research presents SEALONG, an innovative approach to enhancing large language models’ long-context reasoning capabilities through self-improvement techniques. SEALONG represents a significant advancement in addressing critical challenges associated with contextual understanding and reasoning in artificial intelligence systems. By demonstrating the models’ potential to refine their own reasoning processes without external expert intervention, the study offers a promising pathway for continuous model development. The proposed methodology not only improves performance across multiple long-context reasoning tasks but also provides a framework for future research in artificial intelligence. This innovative approach holds substantial implications for the ongoing evolution of large language models, potentially bridging the gap between current AI capabilities and more advanced, human-like reasoning.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post SEALONG: A Self-Improving AI Approach to Long-Context Reasoning in Large Language Models appeared first on MarkTechPost.
Source: Read MoreÂ
