




Generative drug design offers a transformative approach to developing compounds that target pathogenic proteins, enabling exploration within the vast chemical space and fostering the discovery of novel therapeutic agents. Unlike traditional methods, such as high-throughput or virtual screening that rely on predefined molecular libraries with limited diversity, generative models can create entirely new molecules with specific pharmacological properties. This capability is especially valuable for addressing drug resistance and designing compounds for proteins lacking viable candidates. However, many generated molecules need more practical applicability due to a narrow focus on specific drug-related properties, limiting their contribution to the overall drug discovery pipeline.
Recent advancements in deep learning have introduced innovative generative modeling techniques, including autoregressive models, GANs, VAEs, and diffusion models, enabling drug-like compounds to be generated conditioned on target proteins. These methods significantly enhance the potential of target-based drug design, offering access to previously underexplored chemical classes. Despite their promise, these approaches often lack validation through biophysical or biochemical assays, with many generated compounds exhibiting poor drug-like properties, such as limited synthetic accessibility. As a result, while generative models demonstrate the ability to create novel compounds, their real-world impact on drug discovery still needs to be constrained by challenges in translating these compounds into effective drug candidates.
Researchers from Microsoft Research AI for Science and other institutions developed TamGen, a target-aware molecular generation method using a GPT-like chemical language model. TamGen generates drug-like compounds by representing molecules in a sequential SMILES format, integrating modules for target protein-encoding and compound refinement. Applied to tuberculosis drug discovery, TamGen identified 14 compounds targeting the ClpP protease, with the most effective showing an IC50 of 1.9 μM. This approach improves molecular quality, balancing pharmacological activity and synthetic accessibility, demonstrating TamGen’s potential to generate novel candidates for antibiotic development and therapeutic innovation.
TamGen is a framework designed to map protein binding pockets, represented by amino acid sequences and their 3D coordinates, to ligand SMILES strings. The model processes 3D input using embedding layers for amino acids and their coordinates, incorporating data augmentation for rotation and translation invariance. A protein encoder, utilizing distance-aware attention, generates continuous representations, while a contextual encoder based on VAE facilitates diverse ligand generation. Pretrained chemical language models refine the outputs. Training minimizes ligand generation error and enforces latent space regularization. Experiments with datasets like CrossDocked and PDB validated its effectiveness in generating compounds, including tuberculosis inhibitors.
TamGen is a drug design framework combining a GPT-like chemical language model, a Transformer-based protein encoder, and a VAE-based contextual encoder. Pre-trained on 10 million SMILES from PubChem, its compound decoder generates molecules auto-regressively, enabling both target-specific and independent designs. The protein encoder integrates sequence and geometric data, while the contextual encoder facilitates refinement and multi-round optimization. TamGen outperforms other methods in metrics like binding affinity, synthetic accessibility, and diversity and generates compounds 85–394 times faster. Applied to tuberculosis ClpP protease, TamGen produced unique inhibitors with low IC50 values, showcasing its potential for efficient drug discovery.
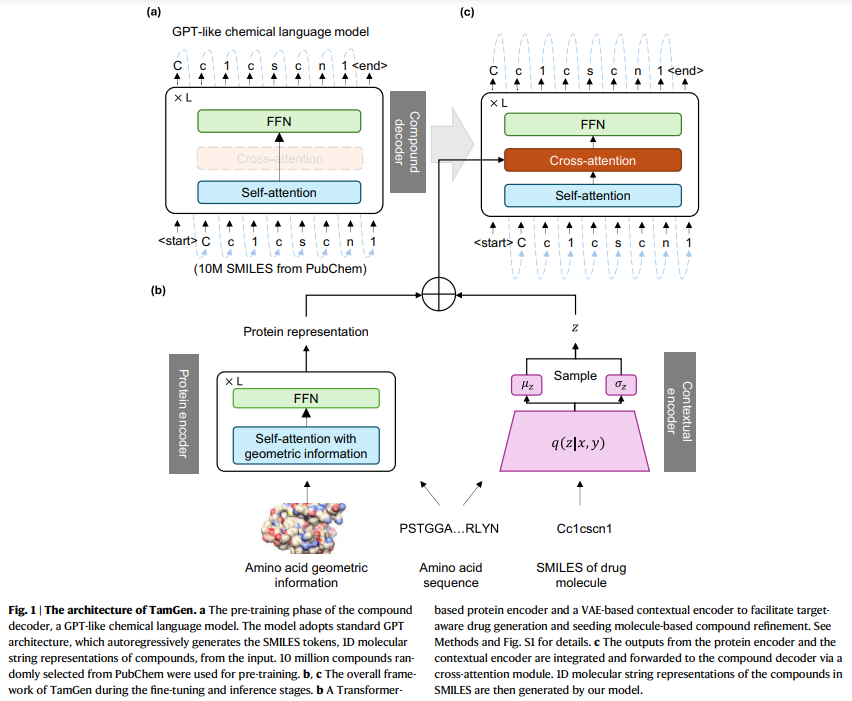
In conclusion, Designing compounds with strong binding affinities to pathogenic proteins can expedite drug discovery by exploring broader chemical spaces through generative AI. TamGen, an AI-driven framework, achieved state-of-the-art results, identifying potent Mycobacterium tuberculosis ClpP protease inhibitors. Its success lies in three aspects: a pre-trained compound decoder generating high-quality molecules, effective protein pocket representation using sequence and geometry, and a VAE-based contextual decoder enabling iterative compound refinement. While offering innovation, challenges remain, including limited in vivo data and synthesis delays. Future improvements aim to integrate 3D generation methods and reinforcement learning for better docking scores, stability, and drug-likeness, enhancing TamGen’s utility.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post TamGen: A Generative AI Framework for Target-Based Drug Discovery and Antibiotic Development appeared first on MarkTechPost.
Source: Read MoreÂ
