




The field of structured generation has become important with the rise of LLMs. These models, capable of generating human-like text, are now tasked with producing outputs that follow rigid formats such as JSON, SQL, and other domain-specific languages. Applications like code generation, robotic control, and structured querying depend heavily on these capabilities. However, ensuring that outputs conform to specific structures without compromising speed or efficiency remains a significant challenge. Structured outputs allow for seamless downstream processing, but the complexity of achieving these results necessitates innovative solutions.
Despite advancements in LLMs, structured output generation continues to be plagued by inefficiencies. One major challenge is managing the computational demands of adhering to grammatical constraints during output generation. Traditional methods like context-free grammar (CFG) interpretation require processing each possible token in the model’s vocabulary, which can exceed 128,000 tokens. Moreover, maintaining stack states to track recursive grammar rules adds to runtime delays. As a result, existing systems often experience high latency and increased resource usage, making them unsuitable for real-time or large-scale applications.
Current tools for structured generation utilize constrained decoding methods to ensure outputs align with predefined rules. These approaches filter out invalid tokens by setting their probabilities to zero at each decoding step. While effective, constrained decoding often needs to improve its efficiency due to evaluating each token against the entire stack state. Also, the recursive nature of CFGs further complicates runtime processing. These challenges have limited the scalability and practicality of existing systems, particularly when handling complex structures or large vocabularies.
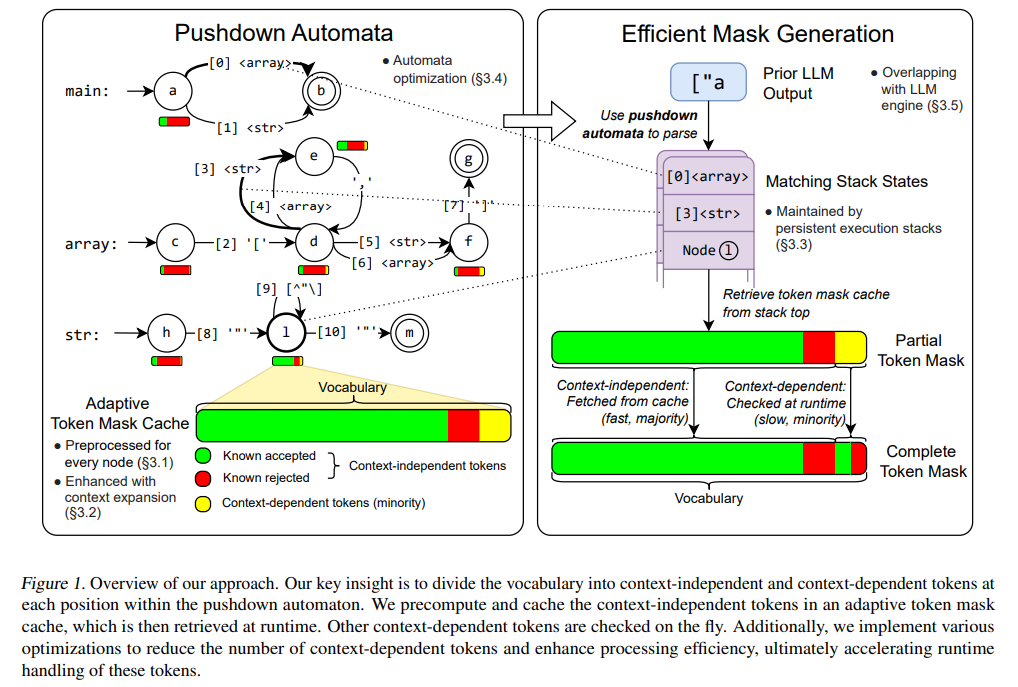
Researchers from Carnegie Mellon University, NVIDIA, Shanghai Jiao Tong University, and the University of California Berkeley developed XGrammar, a groundbreaking structured generation engine to address these limitations. XGrammar introduces a novel approach by dividing tokens into two categories: context-independent tokens that can be prevalidated and context-dependent tokens requiring runtime evaluation. This separation significantly reduces the computational burden during output generation. Also, the system incorporates a co-designed grammar and inference engine, enabling it to overlap grammar computations with GPU-based LLM operations, thereby minimizing overhead.
XGrammar’s technical implementation includes several key innovations. It uses a byte-level pushdown automaton to process CFGs efficiently, enabling it to handle irregular token boundaries and nested structures. The adaptive token mask cache precomputes and stores validity for context-independent tokens, covering over 99% of tokens in most cases. Context-dependent tokens, representing less than 1% of the total, are processed using a persistent execution stack that allows for rapid branching and rollback operations. XGrammar’s preprocessing phase overlaps with the LLM’s initial prompt processing, ensuring near-zero latency for structured generation.
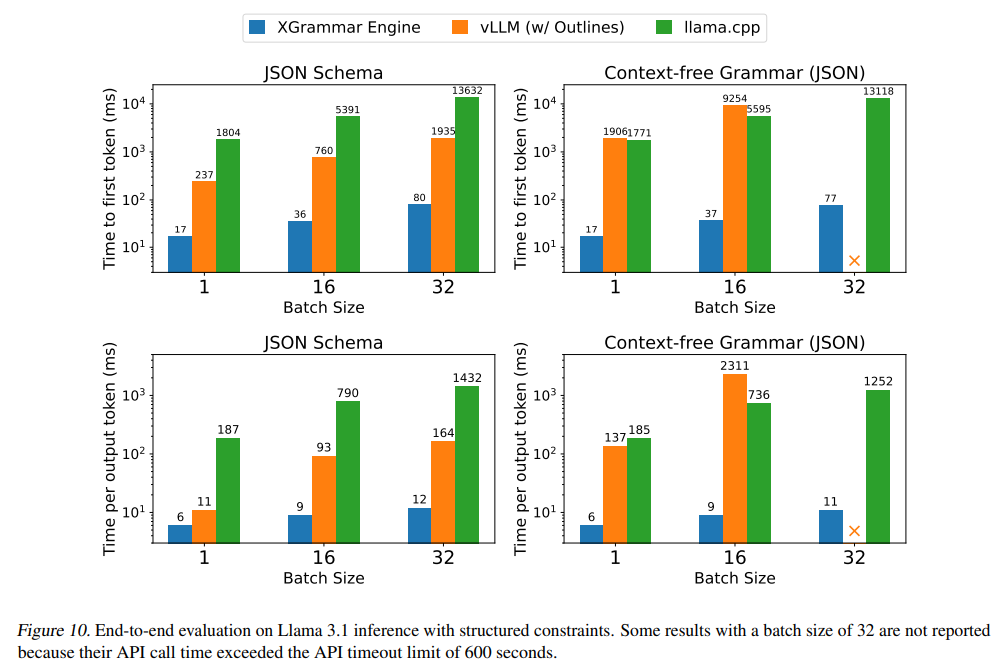
Performance evaluations reveal the significant advantages of XGrammar. For JSON grammar tasks, the system achieves a token mask generation time of less than 40 microseconds, delivering up to a 100x speedup compared to traditional methods. Integrated with the Llama 3.1 model, XGrammar enables an 80x improvement in end-to-end structured output generation on the NVIDIA H100 GPU. Moreover, memory optimization techniques reduce storage requirements to just 0.2% of the original size, from 160 MB to 0.46 MB. These results demonstrate XGrammar’s ability to handle large-scale tasks with unprecedented efficiency.
The researchers’ efforts have several key takeaways:
- Token Categorization: By precomputing context-independent tokens and reducing runtime checks for context-dependent tokens, XGrammar significantly minimizes computational overhead.
- Memory Efficiency: The adaptive token mask cache reduces memory usage to just 0.2% of the original requirements, making it highly scalable.
- Enhanced Performance: With a 100x speedup in CFG processing and an 80x improvement in structured output generation, XGrammar sets a new benchmark for efficiency.
- Cross-Platform Deployment: XGrammar supports a wide range of platforms, including client-side browsers, enabling its use in portable devices like smartphones.
- Integration with LLM Frameworks: The system seamlessly integrates with popular LLM models, such as Llama 3.1, ensuring compatibility and ease of adoption.

In conclusion, XGrammar represents a transformative step in structured generation for large language models. Addressing inefficiencies in traditional CFG processing and constrained decoding offers a scalable, high-performance solution for generating structured outputs. Its innovative techniques, such as token categorization, memory optimization, and platform compatibility, make it an essential tool for advancing AI applications. With results up to 100x speedup and reduced latency, XGrammar sets a new standard for structured generation, enabling LLMs to meet modern AI systems’ demands effectively.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post CMU Researchers Propose XGrammar: An Open-Source Library for Efficient, Flexible, and Portable Structured Generation appeared first on MarkTechPost.
Source: Read MoreÂ
