




The Large Language Models (LLMs) are highly promising in Artificial Intelligence. However, despite training on large datasets covering various languages
and topics, the ability to understand and generate text is sometimes overstated. LLM applications across multiple domains have proven to have little impact on improving human-computer interactions or creating innovative solutions. This is because the deep layers of the LLMS don’t contribute much and, if removed, don’t affect their performance. This underutilization of deep layers shows inefficiency within the models.
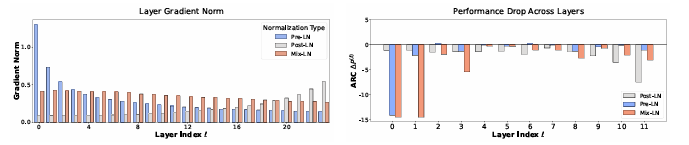
Current methods showed that deeper layers of LLMs contributed little to their performance. Although used to stabilize training, techniques like pre-LN and post-LN showed significant limitations. Pre-LN reduced the magnitude of gradients in deeper layers, limiting their effectiveness, while post-LN caused gradients to vanish in earlier layers. Despite efforts to address these issues through dynamic linear combinations and Adaptive Model Initialization, these techniques do not fully optimize LLM performance.
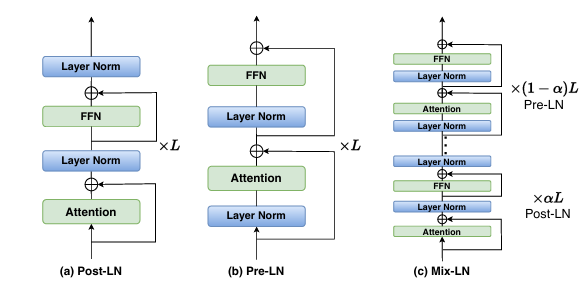
To address this issue, researchers from the Dalian University of Technology, the University of Surrey, the Eindhoven University of Technology, and the University of Oxford proposed Mix-LN. This normalization technique combines the strengths of Pre-LN and Post-LN within the same model. Mix-LN applies Post-LN to the earlier layers and Pre-LN to the deeper layers to ensure more uniform gradients. This approach allows both shallow and deep layers to contribute effectively to training. The researchers evaluated the hypothesis that deeper layers in LLMs were inefficient due to pre-LN. The main difference between post-LN and pre-LN architectures is layer normalization (LN) placement. In post-LN, LN is applied after the residual addition, while in pre-LN, it is used before.
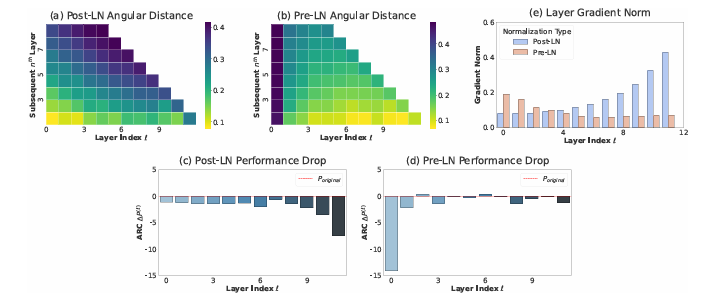
Researchers compared pre- and post-LN models in large-scale open-weight and small-scale in-house LLMs. Metrics such as angular distance and performance drop assessed layer effectiveness. Early layers were less effective in BERT-Large (Post-LN) than in deeper layers. In LLaMa2-7B (Pre-LN), deeper layers were less effective, and pruning them showed minimal performance impact. Researchers observed similar trends in LLaMa-130M, where Pre-LN layers were less effective at deeper levels, and Post-LN maintained better performance in deeper layers. These results suggested that Pre-LN caused the inefficiency of deeper layers.
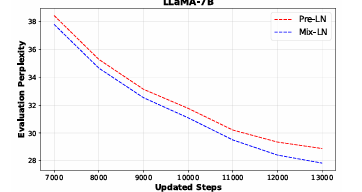
The optimal Post-LN ratio α for Mix-LN was determined through experiments with LLaMA-1B on the C4 dataset. The best performance occurred at α = 0.25, where perplexity was lowest. For the remaining layers, performance decreased but remained higher than the performance recorded by Pre-LN compared to the layers that adopted Post-LN. Mix-LN also supported a broader range of representations and maintained a healthier gradient norm for deeper layers to contribute effectively. Mix-LN achieved significantly low perplexity scores, outperforming other normalization methods.
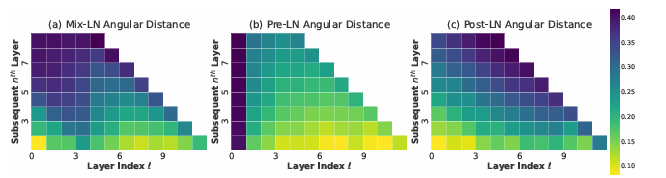
In conclusion, the researchers identified inefficiencies caused by Pre-LN in deep layers of large language models (LLMs) and proposed Mix-LN as a solution. Experiments showed that Mix-LN outperformed both Pre-LN and Post-LN, improving model performance during pre-training and fine-tuning without increasing model size. This approach can act as a baseline for future research, offering a foundation for further enhancements in training deep models and advancing model efficiency and capacity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Mix-LN: A Hybrid Normalization Technique that Combines the Strengths of both Pre-Layer Normalization and Post-Layer Normalization appeared first on MarkTechPost.
Source: Read MoreÂ
