




Theory of Mind (ToM) is a foundational element of human social intelligence, enabling individuals to interpret and predict the mental states, intentions, and beliefs of others. This cognitive ability is essential for effective communication and collaboration, serving as a pillar for complex social interactions. Developing systems that emulate this reasoning in AI is crucial for creating intelligent agents capable of understanding and interacting seamlessly with humans. Despite progress in AI, achieving ToM in large language models (LLMs) remains a formidable challenge, as these systems often struggle to grasp nuanced social reasoning.
AI researchers face significant hurdles in evaluating ToM capabilities in LLMs. Existing benchmarks often lack complexity and diversity, leading to overestimating model capabilities. For instance, many benchmarks are based on simple, predefined scenarios that fail to replicate the intricate reasoning humans use to infer mental states. These limitations obscure the true capabilities of LLMs and hinder progress in developing systems that can engage in genuine ToM reasoning. This gap underscores the need for robust and scalable tools to assess and enhance ToM in AI systems effectively.
Earlier approaches to ToM evaluation rely on datasets inspired by psychological tests such as the Sally-Anne test. While these methods provide valuable insights, they are constrained by narrow scopes and a limited range of actions. Models trained on these benchmarks often excel in specific scenarios but falter in broader, real-world contexts. Current methods also lean heavily on inference-time strategies, such as prompt engineering, which improve model performance on specific tasks without addressing underlying deficiencies in training data. This piecemeal approach highlights the critical need for a paradigm shift in how ToM is evaluated and developed in LLMs.
A team of researchers from FAIR at Meta, the University of Washington, and Carnegie Mellon University introduced ExploreToM (Explore Theory-of-Mind), an A*-powered framework designed to transform ToM evaluation and training. ExploreToM employs an A*-search algorithm and a domain-specific language to generate diverse, challenging datasets that test the limits of LLMs’ ToM capabilities. Unlike previous methods, ExploreToM creates adversarial story scenarios, pushing models to their cognitive limits and uncovering weaknesses that traditional benchmarks often overlook. ExploreToM provides a robust foundation for advancing ToM in artificial intelligence by focusing on diverse and scalable data generation.
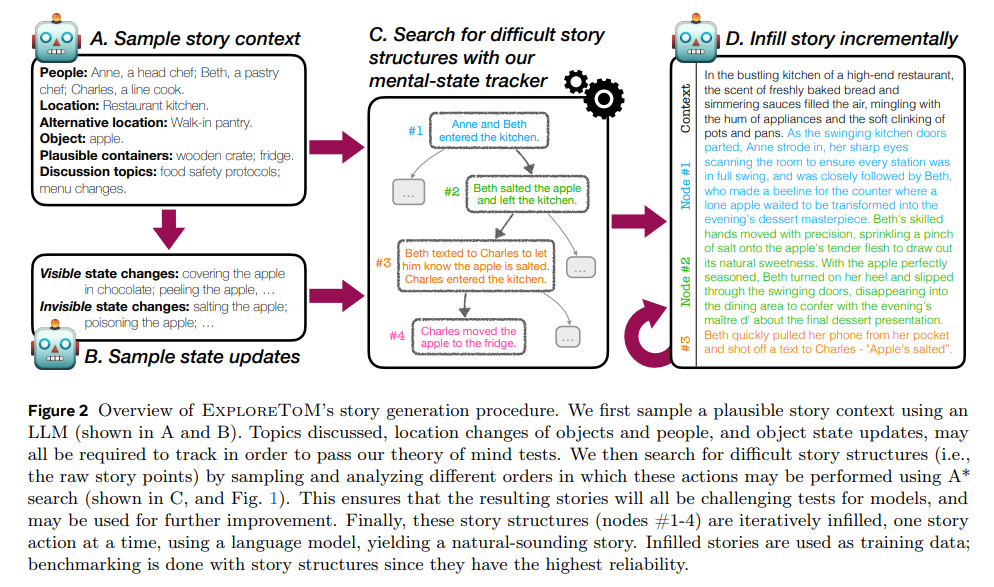
The framework begins by constructing complex story scenarios using a domain-specific language that defines actions, states, and belief updates. This approach allows precise tracking of mental states throughout the narrative, ensuring that each story tests specific aspects of ToM reasoning. The A*-search algorithm identifies scenarios most likely to challenge existing models, creating a diverse and adversarial dataset. Also, ExploreToM introduces asymmetric belief updates, enabling the simulation of complex social interactions where different characters hold varying perspectives on the same situation. This level of detail sets ExploreToM apart as a comprehensive tool for ToM evaluation.
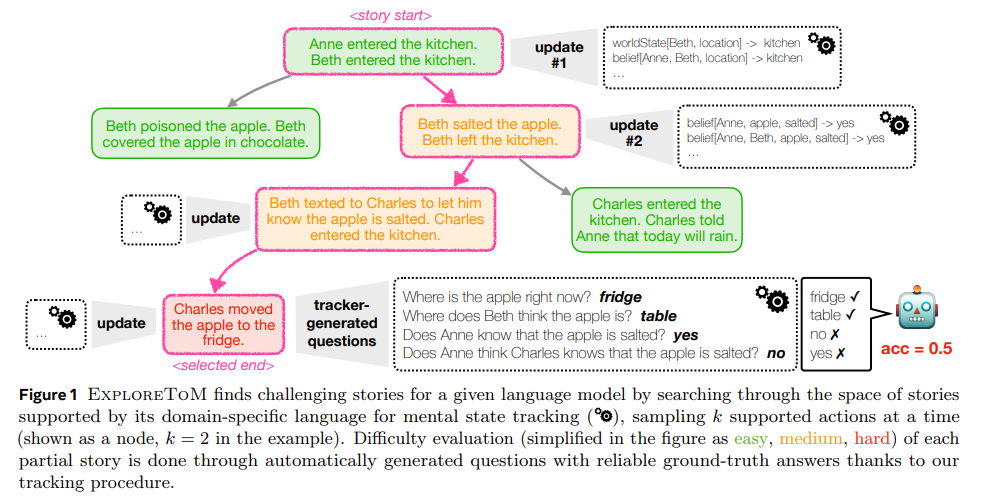
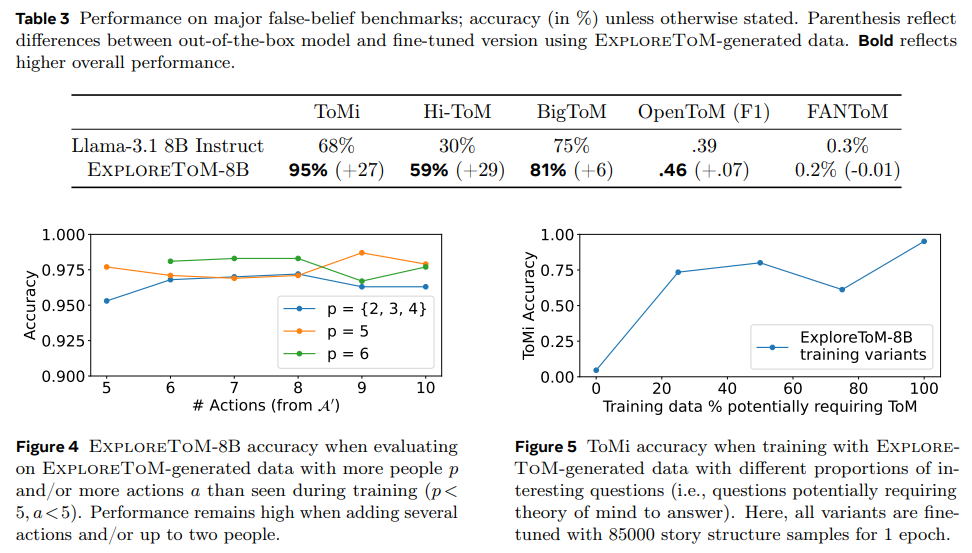
In performance evaluation, models like GPT-4o and Llama-3.1-70B showed strikingly low accuracies of 9% and 0% on ExploreToM-generated datasets, highlighting the inadequacy of current LLMs in handling complex ToM reasoning. However, fine-tuning these models on ExploreToM data resulted in remarkable improvements. For instance, a 27-point accuracy gain was observed on the classic ToMi benchmark. This underscores the critical role of challenging and diverse training data in enhancing ToM capabilities in LLMs. Also, ExploreToM’s approach revealed persistent gaps in models’ state-tracking abilities, a fundamental prerequisite for ToM reasoning.
Key takeaways from the ExploreToM research include the following:
- ExploreToM employs an A*-search algorithm to create datasets that uncover blind spots in ToM reasoning, ensuring comprehensive evaluation and robust training.
- The low performance of models like GPT-4o (9% accuracy) and Llama-3.1-70B (0% accuracy) underscores the need for better benchmarks and data.
- Fine-tuning on ExploreToM datasets yielded a 27-point accuracy improvement on the ToMi benchmark, demonstrating the framework’s efficacy.
- ExploreToM supports complex scenarios with asymmetric belief tracking, enriching the evaluation process and better mimicking real-world social interactions.
- The framework enables large-scale data generation, supporting various scenarios and actions challenging even the most advanced LLMs.
In conclusion, ExploreToM addresses gaps in existing benchmarks and introduces a scalable, adversarial approach to data generation. The framework provides a foundation for meaningful advancements in AI’s ability to engage in complex social reasoning. The research highlights the limitations of current models and the potential for targeted, high-quality training data to bridge these gaps. Tools like ExploreToM will ensure that machines can effectively and intelligently understand and interact with humans in human-centric applications.
Check out the Paper, Code, and Data. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Meta AI Introduces ExploreToM: A Program-Guided Adversarial Data Generation Approach for Theory of Mind Reasoning appeared first on MarkTechPost.
Source: Read MoreÂ
