




Reasoning is critical in problem-solving, allowing humans to make decisions and derive solutions. Two primary types of reasoning are used in problem-solving: forward reasoning and backward reasoning. Forward reasoning involves working from a given question towards a solution, using incremental steps. In contrast, backward reasoning starts with a potential solution and traces back to the original question. This approach is beneficial in tasks that require validation or error-checking, as it helps identify inconsistencies or missed steps in the process.
One of the central challenges in artificial intelligence is incorporating reasoning methods, especially backward reasoning, into machine learning models. Current systems rely on forward reasoning, generating answers from a given data set. However, this approach can result in errors or incomplete solutions, as the model needs to assess and correct its reasoning path. Introducing backward reasoning into AI models, particularly in Large Language Models (LLMs), presents an opportunity to improve the accuracy & reliability of these systems.
Existing methods for reasoning in LLMs focus primarily on forward reasoning, where models generate answers based on a prompt. Some strategies, such as knowledge distillation, attempt to improve reasoning by fine-tuning models with correct reasoning steps. These methods are typically employed during testing, where the model’s generated answers are cross-checked using backward reasoning. Although this improves the model’s accuracy, backward reasoning has yet to be incorporated into the model-building process, limiting this technique’s potential benefits.
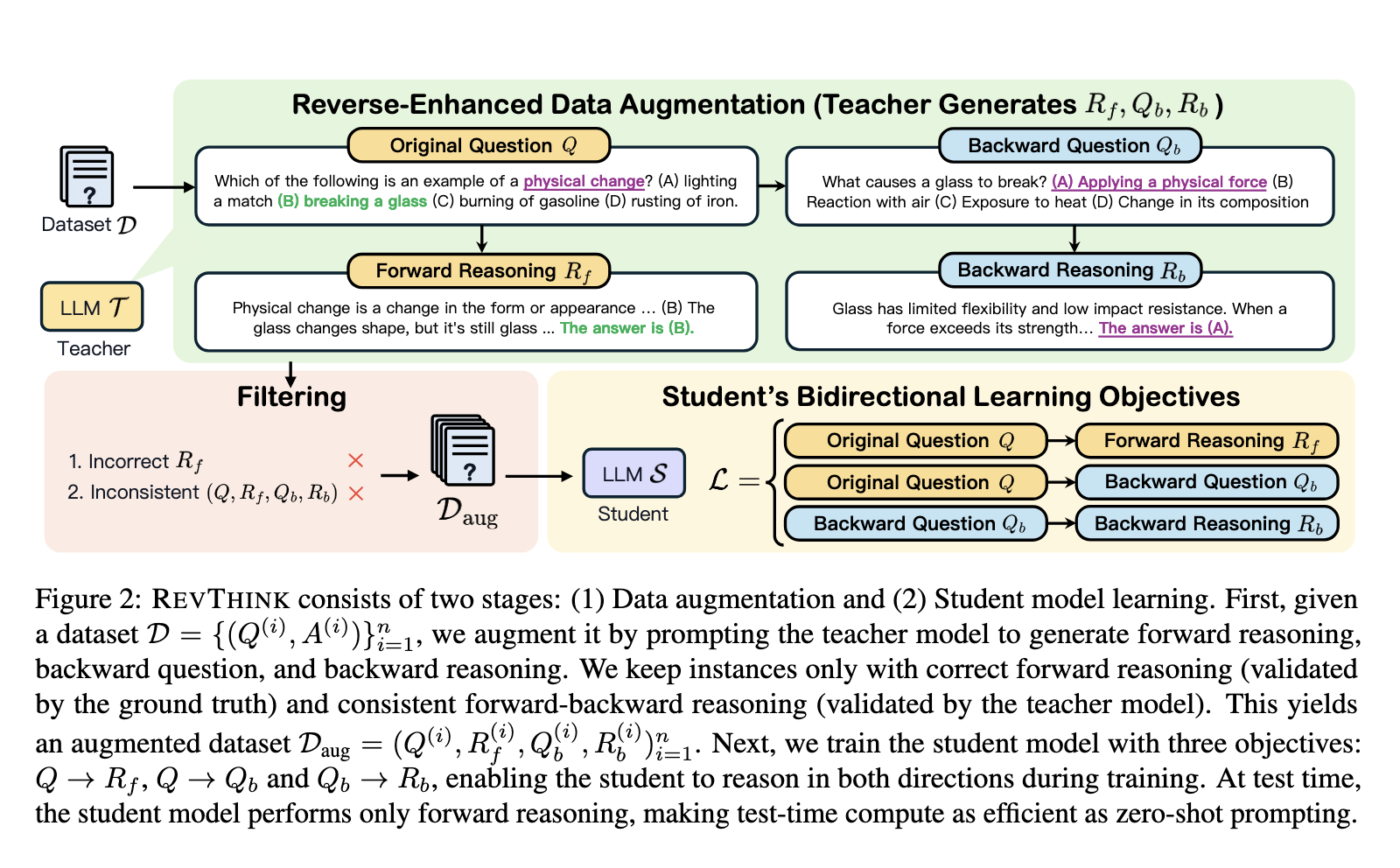
Researchers from UNC Chapel Hill, Google Cloud AI Research, and Google DeepMind introduced the Reverse-Enhanced Thinking (REVTINK) framework. Developed by the Google Cloud AI Research and Google DeepMind teams, REVTINK integrates backward reasoning directly into the training of LLMs. Instead of using backward reasoning merely as a validation tool, this framework incorporates it into the training process by teaching models to handle both forward and backward reasoning tasks. The goal is to create a more robust and efficient reasoning process that can be used to generate answers for a wide variety of tasks.
The REVTINK framework trains models on three distinct tasks: generating forward reasoning from a question, a backward question from a solution, and backward reasoning. By learning to reason in both directions, the model becomes more adept at tackling complex tasks, especially those requiring a step-by-step verification process. The dual approach of forward and backward reasoning enhances the model’s ability to check and refine its outputs, ultimately leading to better accuracy and reduced errors.
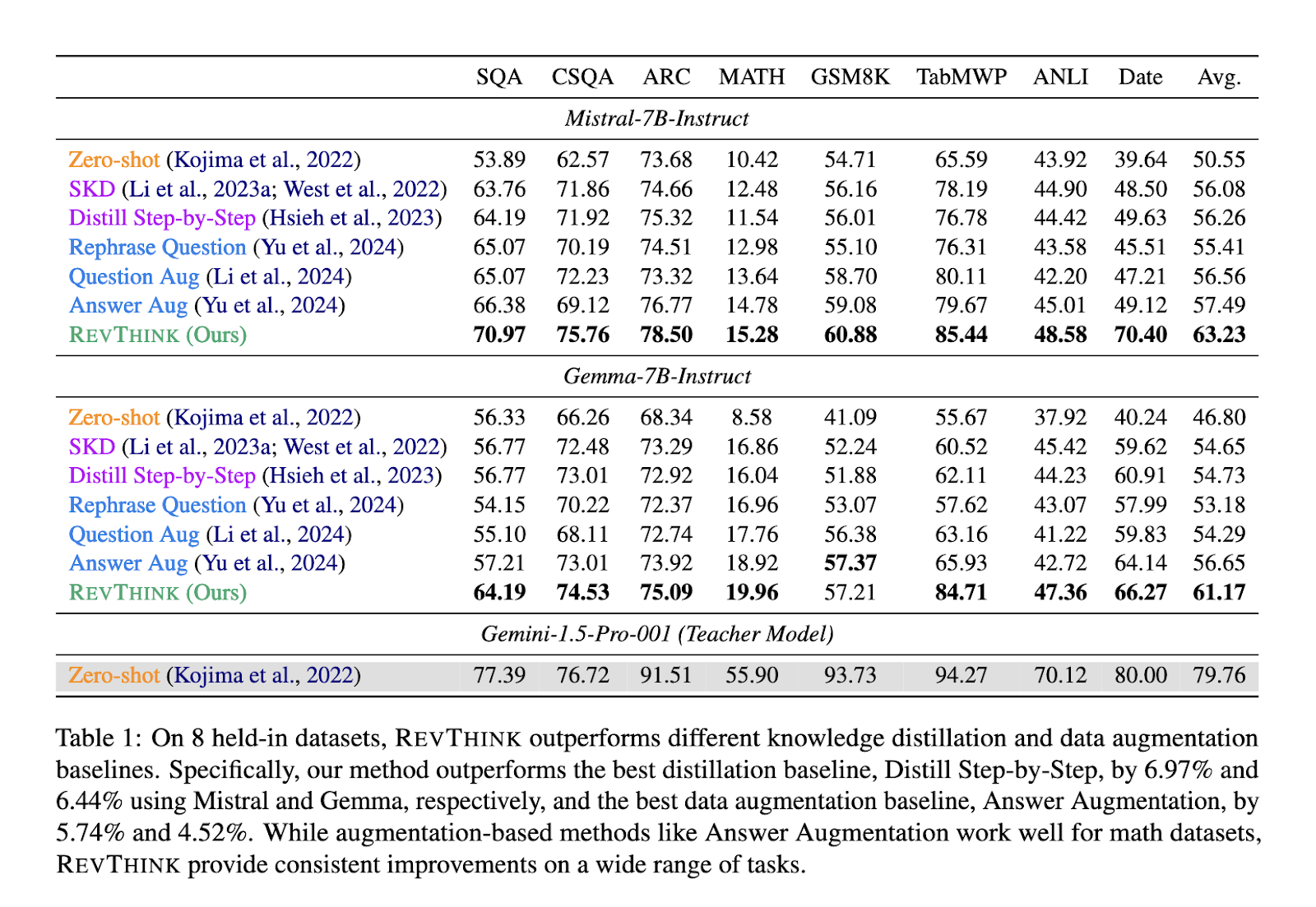
Performance tests on REVTINK showed significant improvements over traditional methods. The research team evaluated the framework on 12 diverse datasets, which included tasks related to commonsense reasoning, mathematical problem-solving, and logical tasks. Compared to zero-shot performance, the model achieved an average improvement of 13.53%, showcasing its ability to understand better and generate answers for complex queries. The REVTINK framework outperformed strong knowledge distillation methods by 6.84%, highlighting its superior performance. Furthermore, the model was found to be highly efficient in terms of sample usage. It required significantly less training data to achieve these results, making it a more efficient option than traditional methods that rely on larger datasets.
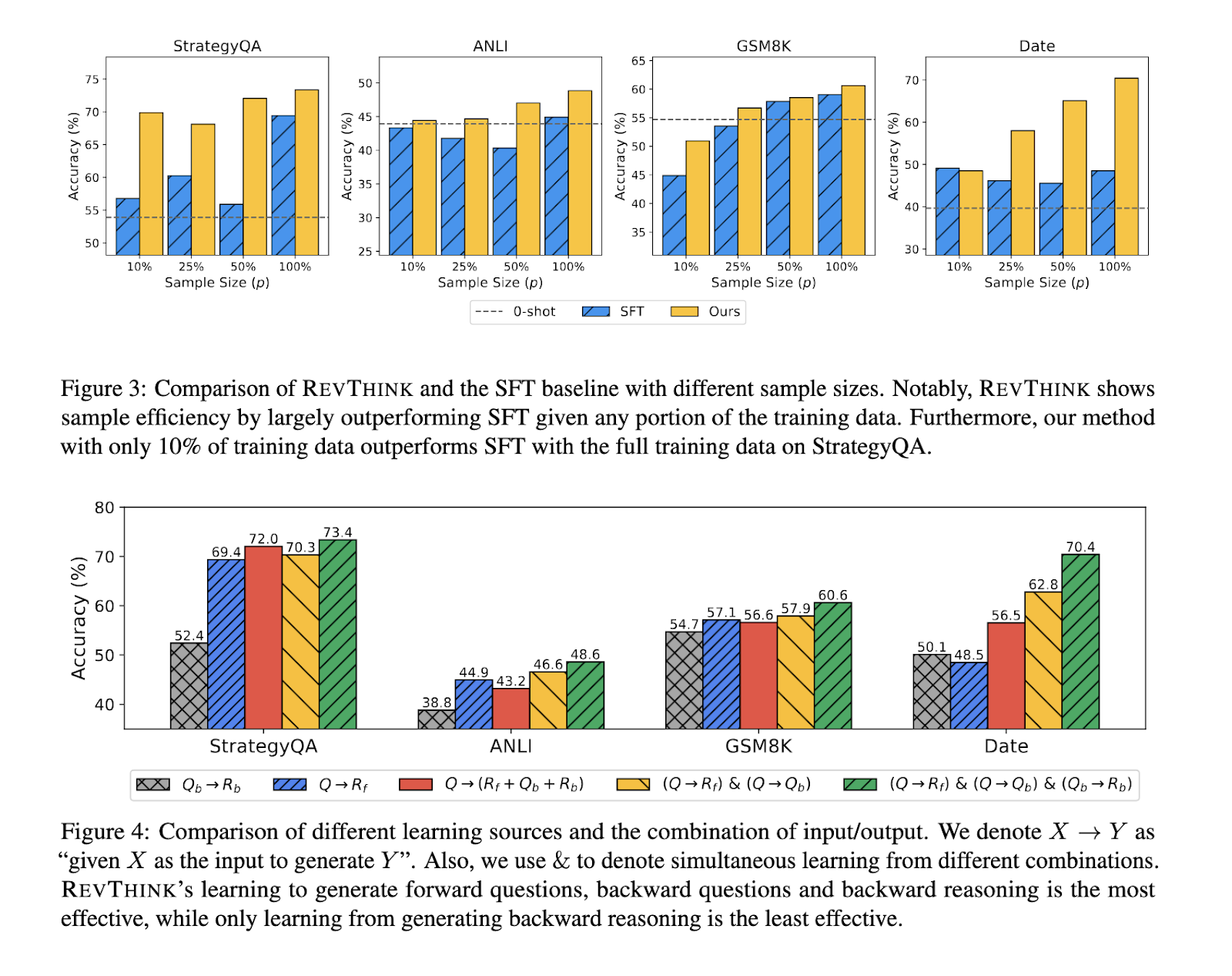
Regarding specific metrics, the REVTINK model’s performance across different domains also illustrated its versatility. The model showed a 9.2% improvement in logical reasoning tasks over conventional models. It demonstrated a 14.1% increase in accuracy for commonsense reasoning, indicating its strong ability to reason through everyday situations. The method’s efficiency also stood out, requiring 20% less training data while outperforming previous benchmarks. This efficiency makes REVTINK an attractive option for applications where training data might be limited or expensive.
The introduction of REVTINK marks a significant advancement in how AI models handle reasoning tasks. The model can generate more accurate answers using fewer resources by integrating backward reasoning into the training process. The framework’s ability to improve performance across multiple domains—especially with less data—demonstrates its potential to revolutionize AI reasoning. Overall, REVTINK promises to create more reliable AI systems that handle various tasks, from mathematical problems to real-world decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Google AI and UNC Chapel Hill Researchers Introduce REVTINK: An AI Framework for Integrating Backward Reasoning into Large Language Models for Improved Performance and Efficiency appeared first on MarkTechPost.
Source: Read MoreÂ
