




Transformer-based Large Language Models (LLMs) face significant challenges in efficiently processing long sequences due to the quadratic complexity of the self-attention mechanism. This will increase their computational and memory demands exponentially with sequence length, so scaling up these models to realistic applications like multi-document summarization, retrieval-based reasoning, or even fine-grained code analysis at the repository level proves impossible. Current approaches fail to manage sequences extending to millions of tokens without considerable computational overhead or loss in accuracy, which creates a major obstacle to their effective deployment in diverse use cases.
Various strategies have been proposed to address these inefficiencies. Sparse attention mechanisms are designed to reduce computational intensity but often fail to preserve the most critical global dependencies, resulting in degraded task performance. Methods for enhancing memory efficiency, such as key-value cache compression and low-rank approximations, reduce resource usage at the cost of scalability and accuracy. Distributed systems such as the Ring Attention improve scalability by distributing computations across several devices. However, these approaches incur significant communication overhead and thus limit their effectiveness in extremely long sequences. Such limitations point to the urgent need for an innovative mechanism that can balance efficiency, scalability, and performance with accuracy.
Researchers from NVIDIA introduced Star Attention, an innovative block-sparse attention mechanism designed to address these challenges. Star Attention essentially breaks an input sequence into smaller blocks, which is preceded by what researchers call an “anchor block,†which holds much information globally. Then blocks process independently on many hosts to significantly reduce computation complexity with the capability to capture patterns globally. The inference processes combine the attention scores for each block using a distributed softmax algorithm that enables efficient global attention while minimizing the data transmission. The integration of the model with prior Transformer-based frameworks is non-intrusive and fine-tuning is not mandatory, making it a quite practical solution to manage lengthy sequences in real-world practice. The technical foundation of Star Attention is a split process. In the first phase, context encoding, each input block is augmented with an anchor block that ensures the model captures global attention patterns. After processing, key-value caches for anchor blocks are discarded to conserve memory. In the second phase, query encoding, and token generation, attention scores are computed locally on each host and combined via distributed softmax, allowing the model to maintain computational efficiency and scalability.
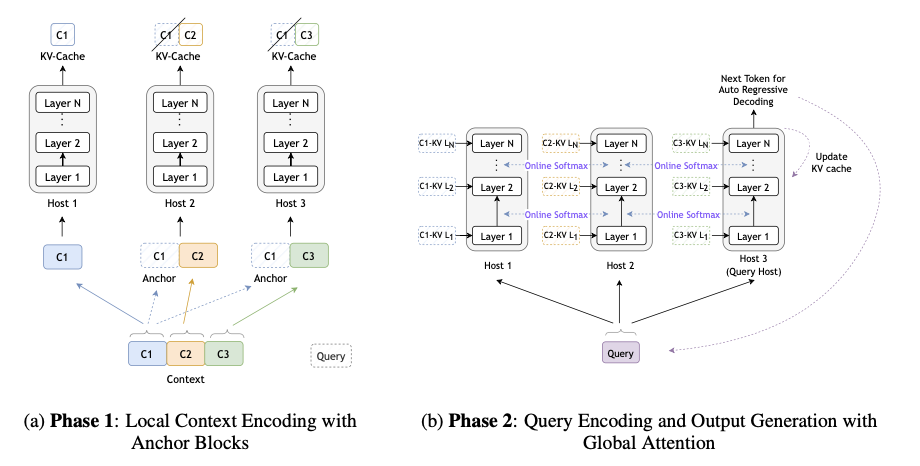
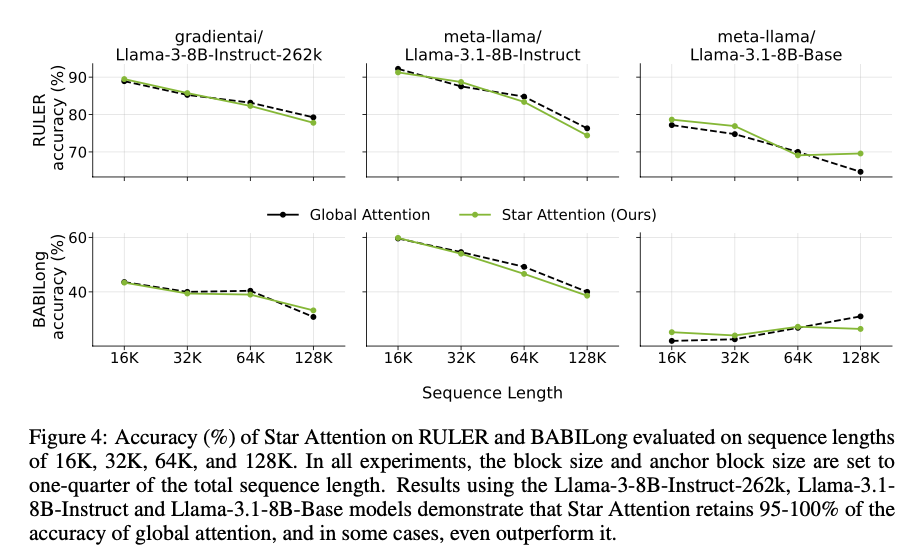
Star Attention was evaluated on benchmarks such as RULER, which includes retrieval and reasoning tasks, and BABILong, which tests long-context reasoning. Over sequences between 16,000 to 1 million tokens long, the models tested – Llama-3.1-8B and Llama-3.1-70B – are being tested, using HuggingFace Transformers and the A100 GPU, which takes advantage of bfloat16 for maximum speed.
Star Attention delivers significant advancements in both speed and accuracy. It achieves up to 11 times faster inference compared to baselines while maintaining 95-100% accuracy across tasks. On the RULER benchmark, it shines in retrieval tasks but its accuracy degrades by a mere 1-3% in more complex multi-hop reasoning scenarios. The BABILong benchmark focused on testing reasoning over longer contexts, and the results are always within the 0-3% range compared with the baseline. It’s also scalable up to 1 million tokens sequence length, making it a strong and flexible candidate that adapts well to highly sequence-dependent applications.

Star Attention establishes a transformative framework for efficient inference in Transformer-based LLMs, addressing key limitations in processing long sequences. Block-sparse attention plus anchor blocks strike the right balance between computational efficiency and accuracy, enabling speedups with significant performance preservation. This advance brings scalable, practical solutions to a wide range of AI applications: reasoning, retrieval, and summarization. Future work will involve designing refinements to anchor mechanisms and improving bottleneck performance in inter-block-communication-dependent tasks with it.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post NVIDIA AI Research Unveils ‘Star Attention’: A Novel AI Algorithm for Efficient LLM Long-Context Inference appeared first on MarkTechPost.
Source: Read MoreÂ
