


Customer satisfaction is critical for insurance companies. Studies have shown that companies with superior customer experiences consistently outperform their peers. In fact, McKinsey found that life and property/casualty insurers with superior customer experiences saw a significant 20% and 65% increase in Total Shareholder Return, respectively, over five years.
A satisfied customer is a loyal customer. They are 80% more likely to renew their policies, directly contributing to sustainable growth. However, one major challenge faced by many insurance companies is the inefficiency of their call centers. Agents often struggle to quickly locate and deliver accurate information to customers, leading to frustration and dissatisfaction.
This article explores how Dataworkz and MongoDB can transform call center operations. By converting call recordings into searchable vectors (numerical representations of data points in a multi-dimensional space), businesses can quickly access relevant information and improve customer service. We’ll dig into how the integration of Amazon Transcribe, Cohere, and MongoDB Atlas Vector Search—as well as Dataworkz’s RAG-as-a-service platform— is achieving this transformation.
From call recordings to vectors: A data-driven approach
Customer service interactions are goldmines of valuable insights. By analyzing call recordings, we can identify successful resolution strategies and uncover frequently asked questions. In turn, by making this information—which is often buried in audio files— accessible to agents, they can give customers faster and more accurate assistance.
However, the vast volume and unstructured nature of these audio files make it challenging to extract actionable information efficiently.
To address this challenge, we propose a pipeline that leverages AI and analytics to transform raw audio recordings into vectors as shown in Figure 1:
Storage of raw audio files: Past call recordings are stored in their original audio format
Processing of the audio files with AI and analytics services (such as Amazon Transcribe Call Analytics): speech-to-text conversion, summarization of content, and vectorization
Storage of vectors and metadata: The generated vectors and associated metadata (e.g., call timestamps, agent information) are stored in an operational data store
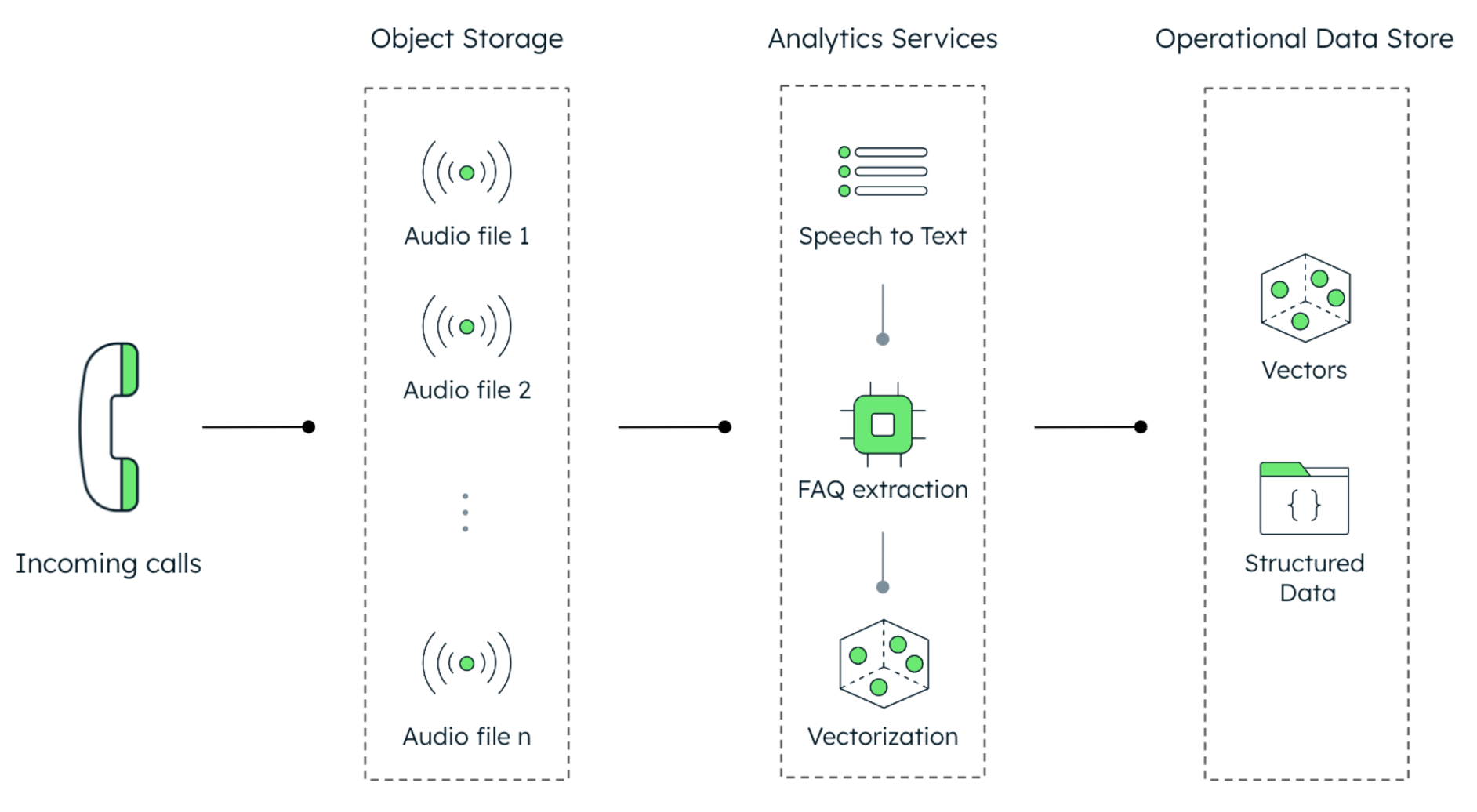
Once the data is stored in vector format within the operational data store, it becomes accessible for real-time applications. This data can be consumed directly through vector search or integrated into a retrieval-augmented generation (RAG) architecture, a technique that combines the capabilities of large language models (LLMs) with external knowledge sources to generate more accurate and informative outputs.
Introducing Dataworkz: Simplifying RAG implementation
Building RAG pipelines can be cumbersome and time-consuming for developers who must learn yet another stack of technologies. Especially in this initial phase, where companies want to experiment and move fast, it is essential to leverage tools that allow us to abstract complexity and don’t require deep knowledge of each component in order to experiment with and realize the benefits of RAG quickly.
Dataworkz offers a powerful and composable RAG-as-a-service platform that streamlines the process of building RAG applications for enterprises. To operationalize RAG effectively, organizations need to master five key capabilities:
ETL for LLMs: Dataworkz connects with diverse data sources and formats, transforming the data to make it ready for consumption by generative AI applications.
Indexing: The platform breaks down data into smaller chunks and creates embeddings that capture semantics, storing them in a vector database.
Retrieval: Dataworkz ensures the retrieval of accurate information in response to user queries, a critical part of the RAG process.
Synthesis: The retrieved information is then used to build the context for a foundational model, generating responses grounded in reality.
Monitoring: With many moving parts in the RAG system, Dataworkz provides robust monitoring capabilities essential for production use cases.
Dataworkz’s intuitive point-and-click interface (as seen in Video 1) simplifies RAG implementation, allowing enterprises to quickly operationalize AI applications. The platform offers flexibility and choice in data connectors, embedding models, vector stores, and language models. Additionally, tools like A/B testing ensure the quality and reliability of generated responses. This combination of ease of use, optionality, and quality assurance is a key tenet of Dataworkz’s “RAG as a Service” offering.
Diving deeper: System architecture and functionalities
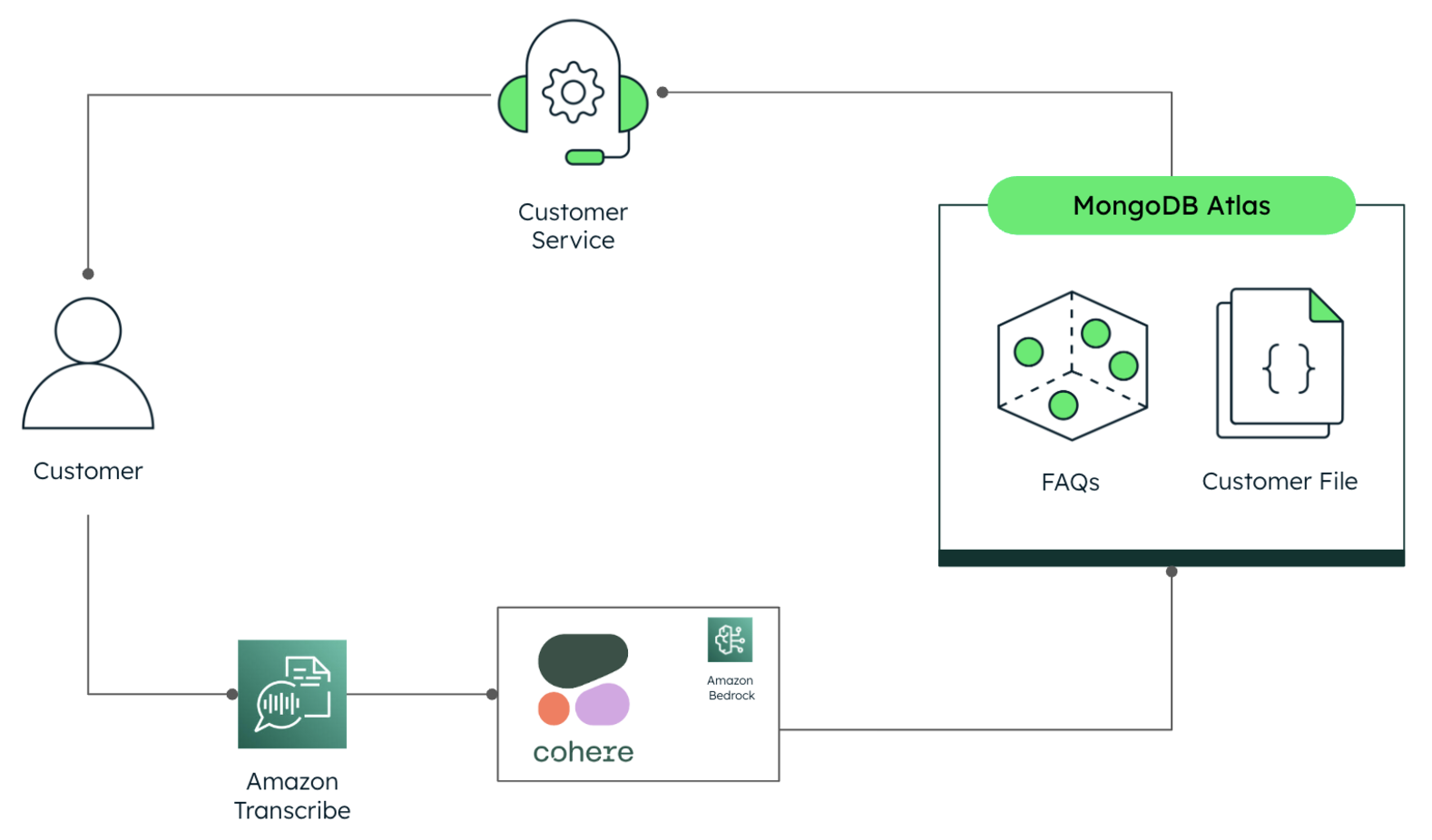
Now that we’ve looked at the components of the pre-processing pipeline, let’s explore the proposed real-time system architecture in detail. It comprises the following modules and functions (see Figure 2):
Amazon Transcribe, which receives the audio coming from the customer’s phone and converts it into text.
Cohere’s embedding model, served through Amazon Bedrock, vectorizes the text coming from Transcribe.
MongoDB Atlas Vector Search receives the query vector and returns a document that contains the most semantically similar FAQ in the database.
Here are a couple of FAQs we used for the demo:
Q: “Can you explain the different types of coverage available for my home insurance?â€
A: “Home insurance typically includes coverage for the structure of your home, your personal belongings, liability protection, and additional living expenses in case you need to temporarily relocate. I can provide more detailed information on each type if you’d like.â€Q: “What is the process for adding a new driver to my auto insurance policy?”
A: “To add a new driver to your auto insurance policy, I’ll need some details about the driver, such as their name, date of birth, and driver’s license number. We can add them to your policy over the phone, or you can do it through our online portal.â€
Note that the question is reported just for reference, and it’s not used for retrieval. The actual question is provided by the user through the voice interface and then matched in real-time with the answers in the database using Vector Search. This information is finally presented to the customer service operator in text form (see Fig. 3).
The proposed architecture is simple but very powerful, easy to implement, and effective. Moreover, it can serve as a foundation for more advanced use cases that require complex interactions, such as agentic workflows, and iterative and multi-step processes that combine LLMs and hybrid search to complete sophisticated tasks.
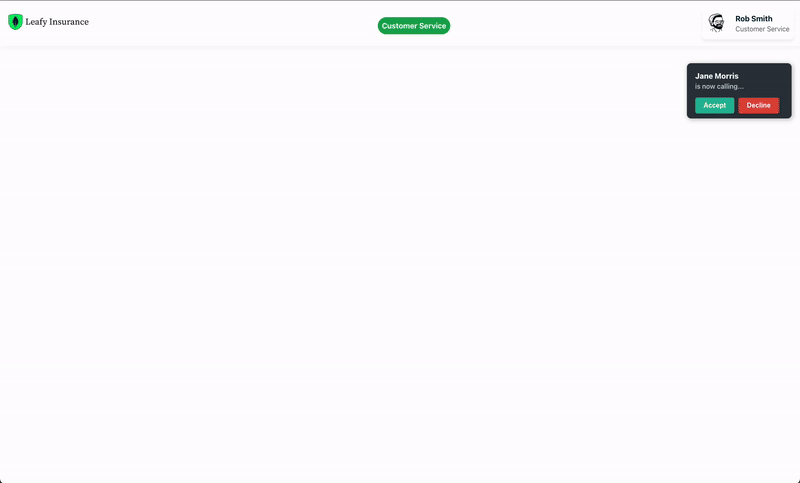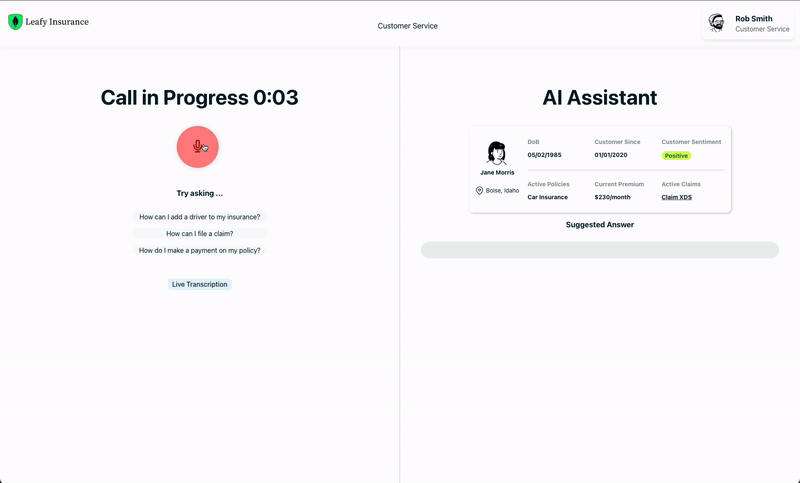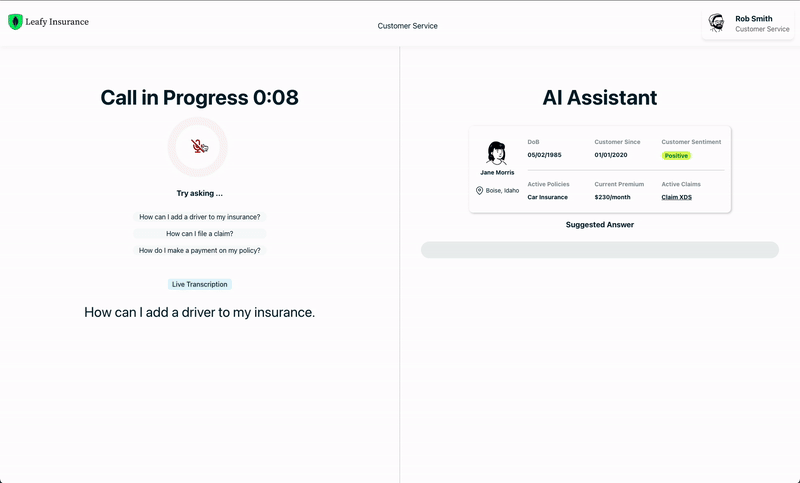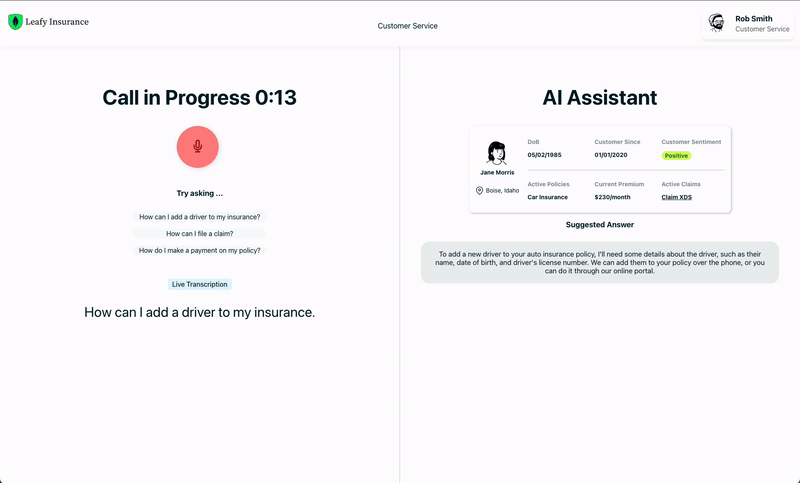
This solution not only impacts human operator workflows but can also underpin chatbots and voicebots, enabling them to provide more relevant and contextual customer responses.
Building a better future for customer service
By seamlessly integrating analytical and operational data streams, insurance companies can significantly enhance both operational efficiency and customer satisfaction. Our system empowers businesses to optimize staffing, accelerate inquiry resolution, and deliver superior customer service through data-driven, real-time insights. To embark on your own customer service transformation, explore our GitHub repository and take advantage of the Dataworkz free tier.
Source: Read More
