

: A Comprehensive Guide")
Introduction to Multiclass Text Classification with LLMsÂ
Multiclass text classification (MTC) is a natural language processing (NLP) task where text is categorized into multiple predefined categories or classes. Traditional approaches rely on training machine learning models, requiring labeled data and iterative fine-tuning. However, with the advent of large language models (LLMs), this task can now be approached differently. Instead of building and training a custom model, we can utilize pre-trained LLMs to classify text using carefully designed prompts, allowing rapid deployment with minimal data requirements and enabling flexibility to adjust classes without retraining.Â
Approaches for MTC-LLMÂ
In MTC-LLM, we generally have two main approaches for utilizing LLMs to achieve classification.Â
Single Classifier with a Multi-Class PromptÂ
Using a single LLM prompt for multi-class text classification involves providing a single, comprehensive prompt that instructs the model on all possible classes, expecting it to classify the text into one of these categories. This approach is simple and straightforward, as it requires only one prompt, making implementation fast and computationally efficient. It also reduces costs, as each classification requires just one LLM call, saving on both usage costs and processing time.Â
However, this approach has notable limitations. When classes are similar, the model may struggle to make precise distinctions, reducing accuracy in nuanced tasks. Additionally, handling all categories within a single prompt can lead to lengthy and complex instructions, which may introduce ambiguity and diminish the model’s reliability. Another critical drawback is the approach’s inability to detect hierarchical relationships within a taxonomy; without recognizing these layers, the model may miss important contextual distinctions between classes that depend on hierarchical categorization.Â
 Â
Hierarchical Sequence of Binary ClassifiersÂ
The hierarchical sequence of binary classifiers approach structures classification as a decision tree, where each node represents a binary decision point. Starting from the top node, the model proceeds through a series of binary classifications, with each LLM call determining whether the text belongs to a specific class. This process continues down the hierarchy until a final classification is achieved.Â
This method provides high accuracy since each binary decision allows the model to make precise, focused choices, which is particularly valuable for distinguishing among nuanced classes. It is also highly adaptable to complex hierarchies, accommodating cases where broad classes may require further subclass distinctions for an accurate classification.Â
However, this approach comes with increased costs and latency, as multiple LLM calls are needed to reach a final classification, making it more expensive and time-consuming. Additionally, managing this approach requires structuring and maintaining numerous prompts and class definitions, adding to its complexity. For use cases where accuracy is prioritized over cost—such as in high-stakes applications like customer service—this hierarchical method is generally the recommended approach.Â
Example Use Case: Intent Detection for Airline Customer ServiceÂ
Let’s consider an airline company using an automated system to respond to customer emails. The goal is to detect the intent behind each email accurately, enabling the system to route the message to the appropriate department or generate a relevant response. This system leverages a hierarchical sequence of binary classifiers, providing a structured approach to intent detection. At each level of the hierarchy, binary classifiers assess whether a specific intent is present, progressively narrowing down the scope of inquiry to arrive at a precise classification.Â
 High-Level Intent ClassificationÂ
At the first stage of the hierarchy, the system categorizes emails into high-level intents to streamline processing and ensure accurate responses. These high-level intents include:Â
General QueriesÂ
 This intent captures broad, information-seeking emails unrelated to specific complaints or actions.   These emails are generally routed to informational workflows or knowledge bases, allowing for automated responses with the required details.  Examples include:Â
- Â Â What is your baggage policy for international flightsÂ
- Â Â Can you provide details about your frequent flyer program?Â
-   What are the requirements for traveling with a pet? Â
Booking IssuesÂ
 Emails under this intent are related to the booking process or flight details. These emails are generally routed to booking support workflows, where sub-classification helps further refine the action required, such as new bookings, modifications, or cancellations.Â
 Examples include:Â
- I want to book a flight to London for next monthÂ
- Can you confirm my ticket for flight number ABC123Â
- I need to reschedule my flight due to a personal emergency. Â
Customer ComplaintsÂ
This category identifies emails expressing dissatisfaction or grievances. These emails are prioritized for customer service escalation, ensuring timely resolution and acknowledgment. Examples include:Â
- Â Â My flight was delayed, and I missed my connection.Â
- Â Â I was charged twice for the same ticket.Â
- Â Â The in-flight entertainment system was not working.Â
Refund RequestsÂ
This category is specific to emails where customers request refunds for canceled flights, overcharges, or other issues. These emails are routed to the refund processing team, where workflows validate the claim and initiate the refund process. Â Examples include:Â
-   I canceled my flight last week but haven’t received my refund yetÂ
- Â Â I was overcharged for baggage fees. Please issue a refundÂ
Special Assistance RequestsÂ
Emails in this category pertain to special accommodations or requests from passengers. These are routed to workflows that handle special services and ensure the requests are appropriately addressed.Â
 Examples include:Â
- Â Â I need wheelchair assistance at the airportÂ
- Â Â Can you provide a meal suitable for someone with a gluten allergyÂ
-   I’m traveling with a child and need a bassinet seatÂ
Lost and Found Inquiries Â
This intent captures emails related to lost items or baggage issues. These emails are routed to the airline’s lost and found or baggage resolution teams.Â
 Examples include:Â
- Â Â I left my laptop on flight XYZ123. How can I retrieve it?Â
- Â Â My checked luggage did not arrive at my destinationÂ
- Â Â I need to report a lost wallet at the airportÂ
Hierarchical Sub-ClassificationÂ
Once the high-level intent is identified, a second layer of binary classifiers operates within each category to refine the classification further. For example:Â
Booking Issues Sub-ClassifiersÂ
- Â Â New BookingsÂ
-   Modifications to Existing Bookings Â
-   Cancellations Â
Customer Complaints Sub-Classifiers Â
-   Flight Delays Â
-   Billing Issues Â
-   Service Quality Â
Refund Requests Sub-ClassifiersÂ
-   Flight Cancellations Â
-   Baggage Fees Â
-   Duplicate Charges Â
Special Assistance Requests Sub-ClassifiersÂ
-   Mobility Assistance Â
-   Dietary Preferences Â
-   Family Travel Needs Â
Lost and Found Sub-Classifiers Â
-   Lost Items in Cabin Â
-   Missing Baggage Â
-   Items Lost at the Airport Â
Benefits of this ApproachÂ
 Scalability
The hierarchical design enables seamless addition of new intents or sub-intents as customer needs evolve, without disrupting the existing classification framework.Â
EfficiencyÂ
By filtering out irrelevant categories at each stage, the system minimizes computational overhead and ensures that only relevant workflows are triggered for each email.Â
Improved AccuracyÂ
Binary classification simplifies the decision-making process, leading to higher precision and recall compared to a flat multiclass classifier.Â
Enhanced Customer ExperienceÂ
Automated responses tailored to specific intents ensure quicker resolutions and more accurate handling of customer inquiries, enhancing overall satisfaction.Â
 Cost-Effectiveness
Automating intent detection reduces reliance on human intervention for routine tasks, freeing up resources for more complex customer service needs.Â
 By categorizing emails into high-level intents like general queries, booking issues, complaints, refunds, special assistance requests, and lost and found inquiries, this automated system ensures efficient routing and resolution. Hierarchical sub-classification adds an extra layer of precision, enabling the airline to deliver fast, accurate, and customer-centric responses while optimizing operational efficiency.Â
The table below is a representation of the complete taxonomy of the intent detection system organized into primary and secondary intents. This taxonomy enables the chatbot to understand and respond more accurately to customer intents, from broad categories down to specific, actionable concerns. Each level helps direct the inquiry to the appropriate team or resource for faster, more effective resolution.Â
Â
| Level | Category | Sub-Category |
| High-Level Intent | General Queries |   |
| Sub-Intent | General Queries | Baggage Policy |
| Sub-Intent | General Queries | Frequent Flyer Program |
| Sub-Intent | General Queries | Travel with Pets |
| High-Level Intent | Booking Issues |   |
| Sub-Intent | Booking Issues | New Bookings |
| Sub-Intent | Booking Issues | Modifications to Existing Bookings |
| Sub-Intent | Booking Issues | Cancellations |
| High-Level Intent | Customer Complaints |   |
| Sub-Intent | Customer Complaints | Flight Delays |
| Sub-Intent | Customer Complaints | Billing Issues |
| Sub-Intent | Customer Complaints | Service Quality |
| High-Level Intent | Refund Requests |   |
| Sub-Intent | Refund Requests | Flight Cancellations |
| Sub-Intent | Refund Requests | Baggage Fees |
| Sub-Intent | Refund Requests | Duplicate Charges |
| High-Level Intent | Special Assistance Requests |   |
| Sub-Intent | Special Assistance Requests | Mobility Assistance |
| Sub-Intent | Special Assistance Requests | Dietary Preferences |
| Sub-Intent | Special Assistance Requests | Family Travel Needs |
| High-Level Intent | Lost and Found Inquiries |   |
| Sub-Intent | Lost and Found Inquiries | Lost Items in Cabin |
| Sub-Intent | Lost and Found Inquiries | Missing Baggage |
| Sub-Intent | Lost and Found Inquiries | Items Lost at the Airport |
Â
The diagram below provides a depiction of this architecture.Â
Â
Â
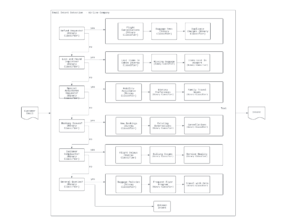
Prompt Structure for a Binary ClassifierÂ
Here’s a sample structure for a binary classifier prompt, where the LLM determines if a customer message is related to a Booking Inquiry.Â
You are an AI language model tasked with classifying whether a customer’s message to the Acme airline company is a “BOOKING INQUIRY.â€Â Â
Definition:Â
A “BOOKING INQUIRY†is a message that directly involves:Â
- Booking a flight: Questions or assistance requests about reserving a new flight.Â
- Modifying a reservation: Any request to change an existing booking, such as altering dates, times, destinations, or passenger details.Â
- Managing a reservation: Tasks like seat selection, cancellations, refunds, or upgrading class, which are tied to the customer’s reservation.Â
- Resolving issues related to booking: Problems like errors in the booking process, confirmation issues, or requests for help with travel-related arrangements.Â
Messages must demonstrate a clear and specific relationship to these areas to qualify as “BOOKING INQUIRY.†General questions about unrelated travel aspects (e.g., baggage fees, flight status, or policies) are classified as “NOT A BOOKING INQUIRY.â€Â
Instructions (Chain-of-Thought Process):Â
For each customer message, follow this reasoning process:Â
- Step 1: Understand the Context – Read the message carefully. If the message is in a language other than English, translate it to English first for proper analysis.Â
- Step 2: Identify Booking-Related Keywords or Phrases – Look for keywords or phrases related to booking (e.g., “book a flight,†“cancel reservation,†“change my seatâ€). Determine if the message is directly addressing the reservation process or related issues.Â
- Step 3: Match to Definition – Compare the content of the message to the definition of “BOOKING INQUIRY.†Determine if it fits one of the following categories:Â
- Booking a flightÂ
- Modifying an existing reservationÂ
- Managing or resolving booking-related issuesÂ
- Step 4: Evaluate Confidence Level – Decide if the message aligns strongly with the definition and the criteria for “BOOKING INQUIRY.†If there is ambiguity or insufficient information classify it as “NOT A BOOKING INQUIRY.â€Â
- Step 5: Provide a Clear Explanation – Based on your analysis, explain your decision in step-by-step reasoning, ensuring the classification is well-justified.Â
Examples:Â
Positive Examples:Â
- Input Message – “I’d like to change my seat for my flight next week.â€Â
 Decision: trueÂ
Reasoning: The message explicitly mentions “change my seat,†which is directly related to modifying a reservation. It aligns with the definition of “BOOKING INQUIRY†as it involves managing a booking.Â
- Input Message – “Can I cancel my reservation and get a refund?â€Â
 Decision: trueÂ
Reasoning: The message includes “cancel my reservation†and “get a refund,†which are part of managing an existing booking. This request is a clear match with the definition of “BOOKING INQUIRY.â€Â
Negative Examples:Â
- Input Message: “How much does it cost to add extra baggage?â€Â
Decision: falseÂ
Reasoning: The message asks about baggage costs, which relates to general travel policies rather than reservations or bookings. There is no indication of booking, modifying, or managing a reservation.Â
- Input Message: “What’s the delay on flight AA123?â€Â
Decision: falseÂ
Reasoning: The message focuses on the status of a flight, not the reservation or booking process. It does not meet the definition of “BOOKING INQUIRY.â€Â
Output: Provide your classification output in the following JSON format:
{
 “decisionâ€: true/false,
 “reasoningâ€: “Step-by-step reasoning for the decision.â€
}Â
Â
Example Code for Binary Classifier Using boto3 and BedrockÂ
In this section, we’ll explore a Python script that implements hierarchical intent detection on user messages by interfacing with a language model (LLM) via AWS Bedrock runtime. The script is designed for flexibility and can be customized to work with other LLM frameworks. Â
“`pythonÂ
import jsonÂ
import boto3Â
from pathlib import PathÂ
from typing import ListÂ
Â
def get_prompt(intent: str) -> str:Â
  “â€â€Â
  Retrieve the prompt template for a given intent from the ‘prompts’ directory.Â
Â
  Assumes that prompt files are stored in a ‘./prompts/’ directory relative to this file,Â
  and that the filenames are in the format ‘{INTENT}-prompt.txt’, e.g., ‘GENERAL_QUERIES-prompt.txt’.Â
Â
  Parameters:Â
    intent (str): The intent for which to retrieve the prompt template.Â
Â
  Returns:Â
    str: The content of the prompt template file corresponding to the specified intent.Â
  “â€â€Â
  # Determine the path to the ‘prompts’ directory relative to this file.Â
  project_root = Path(file).parentÂ
  full_path = project_root / “promptsâ€Â
Â
  # Open and read the prompt file for the specified intent.Â
  with open(full_path / fâ€{intent}-prompt.txtâ€) as file:Â
    prompt = file.read()Â
Â
  return promptÂ
Â
def intent_detection(message: str, decision_list: List[str]) -> str:Â
  “â€â€Â
  Recursively detect the intent of a message by querying an LLM (Anthropic Claude v2).Â
Â
  This function iterates over a list of intents, formats a prompt for each,Â
  and queries the LLM to determine if the message matches the intent.Â
  If a match is found, it may recursively check for more specific sub-intents.Â
Â
  Assumptions:Â
- The prompts explicitly ask the model to return a ‘decision’ with a single response: True or False in JSON format.
    Example: {‘decision’: True}Â
- The prompts contain a variable called ‘input_text’ that is formatted with the user’s message.
- If the model is not able to detect the intent, it will return ‘UNKNOWN’.
Â
  Parameters:Â
    message (str): The user’s message for which to detect the intent.Â
    decision_list (List[str]): A list of intent names to evaluate.Â
Â
  Returns:Â
    str: The detected intent name, or ‘UNKNOWN’ if no intent is matched.Â
  “â€â€Â
  # Create a client for AWS Bedrock runtime to interact with the LLM.Â
  client = boto3.client(“bedrock-runtimeâ€, region_name=â€us-east-1″)Â
Â
  for intent in decision_list:Â
    # Retrieve and format the prompt template with the user’s message.Â
    prompt_template = get_prompt(intent)Â
    prompt = prompt_template.format(input_text=message)Â
Â
    # Construct the request body for the LLM API call.Â
    body = json.dumps(Â
      {Â
        “anthropic_versionâ€: “bedrock-2023-05-31â€,Â
        “max_tokensâ€: 4096,Â
        “temperatureâ€: 0.0,Â
        “messagesâ€: [Â
          {Â
            “roleâ€: “userâ€,Â
            “contentâ€: [Â
              {“typeâ€: “textâ€, “textâ€: prompt}Â
            ]Â
          }Â
        ]Â
      }Â
    )Â
Â
    # Invoke the LLM model with the constructed body.Â
    raw_response = client.invoke_model(Â
      modelId=â€anthropic.claude-3-5-sonet-20240620-v1:0″,Â
      body=bodyÂ
    )Â
Â
    # Read and parse the response from the LLM.Â
    response = raw_response.get(“bodyâ€).read()Â
    response_body = json.loads(response)Â
    llm_text_response = response_body.get(“contentâ€)[0].get(“textâ€)Â
Â
    # Parse the LLM’s text response to JSON.Â
    llm_response_json = json.loads(llm_text_response)Â
Â
    # Check if the LLM decided that the message matches the current intent.Â
    if llm_response_json.get(“decisionâ€, False):Â
      transitional_intent = intentÂ
      break  # Exit the loop as we’ve found a matching intent.Â
    else:Â
      # If not matched, set the transitional intent to ‘UNKNOWN’.Â
      transitional_intent = “UNKNOWNâ€Â
Â
  # Define the root intents that may have more specific sub-intents.Â
  root_intents = [“GENERAL_QUERIESâ€, “BOOKING_ISSUESâ€, “CUSTOMER_COMPLAINTSâ€]Â
Â
  # If a matching root intent is found, recursively check for more specific intents.Â
  if transitional_intent in root_intents:Â
    # Mapping of root intents to their related sub-intents.Â
    intent_definition = {Â
      “GENERAL_QUERIES_related_intentsâ€: [Â
        “DESTINATION_INFORMATIONâ€,Â
        “LOYALTY_PROGRAM_DETAILSâ€,Â
        “FLIGHT_SCHEDULESâ€,Â
        “AIRLINE_POLICIESâ€,Â
        “CHECK_IN_PROCEDURESâ€,Â
        “IN_FLIGHT_SERVICESâ€,Â
        “CANCELLATION_POLICYâ€Â
      ],Â
      “BOOKING_ISSUES_related_intentsâ€: [Â
        “FLIGHT_CHANGEâ€,Â
        “SEAT_SELECTIONâ€,Â
        “BAGGAGEâ€Â
      ],Â
      “CUSTOMER_COMPLAINTS_related_intentsâ€: [Â
        “DELAYâ€,Â
        “SERVICE_DISSATISFACTIONâ€,Â
        “SAFETY_CONCERNSâ€Â
      ]Â
    }Â
    # Recursively call intent_detection with the related sub-intents.Â
    return intent_detection(Â
      message,Â
      intent_definition.get(fâ€{transitional_intent}_related_intentsâ€)Â
    )Â
  else:Â
    # Return the detected intent or ‘UNKNOWN’ if none matched.Â
    return transitional_intentÂ
Â
def main(message: str) -> str:Â
  “â€â€Â
  Main function to initiate intent detection on a user’s message.Â
Â
  Parameters:Â
    message (str): The user’s message for which to detect the intent.Â
Â
  Returns:Â
    str: The detected intent name, or ‘UNKNOWN’ if no intent is matched.Â
  “â€â€Â
  # Start intent detection with the root intents.Â
  return intent_detection(Â
    message=message,Â
    decision_list=[Â
      “GENERAL_QUERIESâ€,Â
      “BOOKING_ISSUESâ€,Â
      “CUSTOMER_COMPLAINTSâ€Â
    ]Â
  )Â
Â
Â
if name == “main“:Â
  message = “â€â€Â
Hello,Â
Â
I’m planning to travel next month and wanted to ask about your airline’s policies. Could you please provide information on:Â
Â
Your refund and cancellation policies.Â
Rules regarding carrying liquids or other restricted items.Â
Any COVID-19 safety measures still in place.Â
Â
Looking forward to your response.Â
  “â€â€Â
  print(main(message=message))Â
Â
Â
This module is part of an automated email processing system designed to analyze customer messages, detect their intent, and generate structured responses based on the analysis. The system employs a large language model API to perform Natural Language Processing (NLP), classifying emails into primary intents such as “General Queries,†“Booking Issues,†or “Customer Complaints.â€Â
 Â
Evaluation GuidelinesÂ
To comprehensively evaluate the performance of a hierarchical sequence of binary classifiers for multiclass text classification using LLMs, a well-constructed ground truth dataset is critical. This dataset should be meticulously designed to serve multiple purposes, ensuring both the overall system and individual classifiers are assessed accurately.Â
Dataset Design ConsiderationsÂ
- Balanced Dataset for Overall Evaluation:Â
The ground truth dataset must encompass a balanced representation of all intent categories to evaluate the system holistically. This enables the calculation of critical overall metrics such as accuracy, macro-precision, macro-recall, and micro-precision. A balanced dataset ensures that no specific category disproportionately influences these metrics, providing a fair measure of the system’s performance across all intents.Â
- Per-Classifier Evaluation:Â
Each binary classifier in the hierarchy should also be evaluated individually. To achieve this, the dataset must contain balanced positive and negative samples for each classifier. This balance is essential to calculate metrics such as accuracy, precision, recall, and F1-score for each individual classifier, enabling targeted performance analysis and iterative improvements at every level of the hierarchy.Â
- Negative Sample Creation:Â
Designing negative samples is a critical aspect of the dataset preparation process. Negative samples should be created using common sense principles to reflect real-world scenarios accurately:Â
- Diversity: Negative samples should be diverse to simulate various input conditions, preventing classifiers from overfitting to narrow definitions of “positive†and “negative†examples.Â
- Relevance for Lower-Level Classifiers: For classifiers deeper in the hierarchy, negative samples need not include examples from unrelated categories. For instance, in a “Flight Change†classifier, negative samples can exclude intents related to “Safety Concerns†or “In-Flight Entertainment.†This specificity helps avoid unnecessary complexity and confusion, focusing the classifier on its immediate decision boundary.Â
Metrics for EvaluationÂ
- Overall System Metrics:Â
- Accuracy: The ratio of correctly classified samples to total samples, indicating the system’s general performance.Â
- Macro and Micro Precision & Recall: Macro metrics weigh each class equally, providing insights into system performance for underrepresented categories. Micro metrics, on the other hand, weigh classes proportionally to their sample sizes, offering a perspective on system performance for frequently occurring categories.Â
- Classifier-Level Metrics:Â
- Each binary classifier must be evaluated independently using accuracy, precision, recall, and F1-score. These metrics help pinpoint weaknesses in individual classifiers, which can then be addressed through retraining, hyperparameter tuning, or data augmentation.Â
- Cost per Classification:Â
- Tracking the computational or financial cost per classification is vital, especially in scenarios where resource efficiency is a priority. This metric helps balance the trade-off between model performance and operational budget constraints.Â
Additional ConsiderationsÂ
- Dataset Size:Â
- The dataset should be large enough to capture variations in intent expressions while ensuring each classifier receives sufficient positive and negative samples for robust training and evaluation.Â
- Data Augmentation:Â
- Techniques such as paraphrasing, synonym replacement, or noise injection can be employed to expand the dataset and improve classifier generalization.Â
- Cross-Validation:Â
- Employing techniques like k-fold cross-validation can ensure that the evaluation metrics are not biased by a specific train-test split, providing a more reliable assessment of the system’s performance.Â
- Real-World Testing:Â
- In addition to ground truth datasets, testing the system on real-world, unstructured data can reveal gaps in performance and help fine-tune classifiers to handle practical scenarios effectively.Â
By adhering to these principles, the evaluation process will yield a thorough understanding of both the end-to-end system’s performance and the individual strengths and weaknesses of each classifier, guiding data-driven refinements and ensuring robust, scalable deployment.Â
Additional Best Practices for Multiclass Text Classification Using LLMsÂ
Prompt CachingÂ
Prompt caching is a powerful technique for improving efficiency and reducing latency in applications with repeated queries or predictable user interactions. By caching prompts and their corresponding LLM-generated outputs, systems can avoid redundant API calls, thereby improving response times and lowering operational costs.Â
- Implementation Across Popular LLM SuitesÂ
- Anthropic: Anthropic’s models support prompt caching is done by marking specific parts of your prompt—such as tool definitions, system instructions, or lengthy context—with the cache_control parameter in your API requests. For example, you might include the entire text of a book in your prompt and cache it, allowing you to ask multiple questions about the text without reprocessing it each time. To enable this feature, include the header anthropic-beta: prompt-caching-2024-07-31 in your API calls, as prompt caching is currently in beta. By structuring your prompts with static content at the beginning and dynamic, user-specific content at the end, and by strategically marking cacheable sections, you can optimize performance, reduce latency, and lower operational costs when working with Anthropic’s language models.Â
- ChatGPT (OpenAI): To implement OpenAI’s Prompt Caching and optimize your application’s performance, structure your prompts so that static or repetitive content—like system prompts and common instructions—is placed at the beginning, while dynamic, user-specific information is appended at the end. This setup leverages exact prefix matching, increasing the likelihood of cache hits for prompts longer than 1,024 tokens. When the prefix of a prompt matches a cached entry, the system reuses the cached processing results, reducing latency by up to 80% and cutting costs by 50% for lengthy prompts. The caching mechanism operates automatically, requiring no additional code changes, and is specific to your organization to maintain data privacy. Cached prompts remain active for 5 to 10 minutes of inactivity and can persist up to an hour during off-peak periods. By following these implementation strategies, you can enhance API efficiency and reduce operational costs when interacting with OpenAI’s language models.Â
- Gemini (Google): Context caching in the Gemini API enables you to reduce processing time and costs by caching large input tokens that are reused across multiple requests. To implement this, you first upload your content (such as large documents or files) using the Files API. Then, you create a cache with a specified Time to Live (TTL) using the CachedContent.create() method, which stores the tokenized content for a duration you choose. When generating responses, you construct a GenerativeModel that references this cached content, allowing the model to access the cached tokens without reprocessing them. This is particularly effective for applications like chatbots with extensive system instructions or repetitive analysis tasks, as it minimizes redundant token processing and optimizes overall performance.Â
- Best Practices for Implementing Caching with Large Language Models (LLMs):Â
- Structure Prompts Effectively:Â
- Static Content First: Place static or repetitive content—such as system prompts, instructions, context, or examples—at the beginning of your prompt.Â
- Dynamic Content Last: Append variable or user-specific information at the end. This increases the likelihood of cache hits due to exact prefix matching.Â
- Leverage Exact Prefix Matching:Â
- Ensure that the cached sections of your prompts are identical across requests. Even minor differences can prevent cache hits.Â
- Use consistent formatting, wording, and structure for the static parts of your prompts.Â
- Utilize Caching for Long Prompts:Â
- Caching is most beneficial for prompts that exceed certain token thresholds (e.g., 1,024 tokens).Â
- For lengthy prompts with repetitive elements, caching can significantly reduce latency and cost.Â
- Mark Cacheable Sections Appropriately:Â
- Use available API features (such as cache_control parameters or specific headers) to designate cacheable sections in your prompts.Â
- Clearly define cache boundaries to optimize caching efficiency.Â
- Set Appropriate Time to Live (TTL):Â
- Adjust the TTL based on how frequently the cached content is accessed.Â
- Longer TTLs are advantageous for content that is reused often, while shorter TTLs prevent stale data in dynamic environments.Â
- Be Mindful of Model and API Constraints:Â
- Ensure that you’re using models that support caching features.Â
- Be aware of minimum token counts and other limitations specific to the LLM you’re using.Â
- Understand Pricing and Cost Implications:Â
- Familiarize yourself with the pricing model for caching, including any costs for cache writes, reads, and storage duration.Â
- Balance the cost of caching against the benefits of reduced processing time and lower per-request costs.Â
- Handle Cache Invalidation and Updates:Â
- Implement mechanisms to update or invalidate caches when the underlying content changes.Â
- Be prepared to handle cache misses gracefully by processing the full prompt when necessary.Â
Â
Temperature SettingsÂ
The temperature parameter is critical in controlling the randomness and creativity of an LLM’s output.Â
Low Temperature (e.g., 0.2)Â
A low temperature setting makes the model’s outputs more deterministic by prioritizing higher-probability tokens. This is ideal for:Â
- Classification-oriented tasks requiring consistent responses.Â
- Scenarios where factual accuracy is critical.Â
- Narrow decision boundaries, such as binary classifiers in the hierarchy.Â
High Temperature (e.g., 0.8–1.0)Â
Higher temperature settings introduce more randomness, making the model explore diverse possibilities. This is useful for:Â
- Generating creative text, brainstorming ideas, or handling ambiguous inputs.Â
- Scenarios where the intent is not well-defined and may benefit from exploratory responses.Â
Best Practices for Multiclass HierarchiesÂ
- Use low temperatures for top-level binary classifiers where intent boundaries are clear.Â
- Experiment with slightly higher temperatures for ambiguous or nuanced intent categories to capture edge cases during evaluation phases.Â
Adding Reasoning to the PromptÂ
Encouraging LLMs to reason step-by-step improves their ability to handle ambiguous or complex cases. This can be achieved by explicitly prompting the model to break down the classification process. For instance:Â
- Use phrases like “First, analyze the input for relevant keywords. Then, decide the most appropriate intent based on the following rules.â€Â
- This approach helps mitigate errors in cases where multiple intents may appear similar by providing a logical framework for decision-making.Â
Â
Â
Prompt Optimization with Meta-PromptingÂ
Meta-prompts are prompts about prompts. They guide the LLM to follow specific rules or adhere to structured formats for better interpretability and accuracy. Examples include:Â
- Defining constraints, such as “Respond only with ‘Yes’ or ‘No.’â€Â
- Setting explicit rules, such as “If the input mentions scheduling changes, classify as ‘Flight Change.’â€Â
- Clarifying ambiguous instructions, such as “If unsure, classify as ‘Miscellaneous’ and provide an explanation.â€Â
Â
Fine-Tuning Other Key LLM ParametersÂ
- Max Tokens – Control the length of the output to avoid excessive verbosity or truncation. For classification tasks, limit the tokens to the minimal response necessary (e.g., “Yes,†“No,†or a concise class label).Â
- Top-p Sampling (Nucleus Sampling) – Instead of selecting tokens based on temperature alone, top-p sampling chooses from a subset of tokens whose cumulative probability adds up to a specified threshold. For deterministic tasks, set top-p close to 0.9 to balance precision and diversity.Â
- Stop Sequences – Define stop sequences to terminate outputs gracefully, ensuring outputs do not contain unnecessary or irrelevant continuations.Â
Iterative Prompt RefinementÂ
Iterative prompt refinement is a crucial process for continuously improving the performance of LLMs in hierarchical multiclass classification tasks. By systematically analyzing errors, refining prompts, and validating changes, you can ensure the system evolves to handle complex and ambiguous scenarios more effectively. A structured “prompt refinement pipeline†can greatly enhance this process by combining meta-prompts and ground truth datasets for evaluation.Â
The Prompt Refinement PipelineÂ
A prompt refinement pipeline is an automated or semi-automated framework that systematically refines, tests, and evaluates prompts. It consists of the following components:Â
- Meta-Prompt for RefinementÂ
Use an LLM itself to refine existing prompts by generating more concise, effective, or logically robust alternatives. A meta-prompt asks the model to analyze and improve a given prompt. For example:Â
- Input Meta-Prompt:Â
- “The following prompt is used for a binary classifier in a hierarchical text classification task. Suggest improvements to make it more specific, avoid ambiguity, and handle edge cases better. Also, propose an explanation for why your suggestions improve the prompt. Current prompt: [insert prompt].â€Â
- Output: The model may suggest rewording, adding explicit constraints, or including step-by-step reasoning logic. These suggestions can then be iteratively tested.Â
- Ground Truth Dataset for EvaluationÂ
Use a ground truth dataset to validate refined prompts against pre-labeled examples. This ensures that improvements suggested by the meta-prompt are objectively tested. Key steps include:Â
- Evaluate the refined prompt on classification accuracy, precision, recall, and F1-score using the ground truth dataset.Â
- Compare these metrics against the original prompt to ensure genuine improvement.Â
- Use misclassified examples to further identify weaknesses and refine prompts iteratively.Â
- Automated Testing and Feedback LoopÂ
Implement an automated system to:Â
- Test the refined prompt on a validation set.Â
- Log performance metrics, including correct classifications, errors, and cases where ambiguity persists.Â
- Highlight specific prompts or input types that consistently underperform for further manual refinement.Â
- Version Control and ExperimentationÂ
Maintain a version-controlled repository for prompts. Track:Â
- Changes made during each refinement cycle.Â
- Associated performance metrics.Â
- Rationale behind prompt modifications. This documentation provides a knowledge base for future refinements and prevents regressions.Â
Benefits of a Prompt Refinement PipelineÂ
- Systematic ImprovementÂ
A structured approach ensures refinements are not ad hoc but are guided by data-driven insights and measurable results.Â
- ScalabilityÂ
By automating key aspects of the refinement process, the pipeline scales effectively with larger datasets and more complex classification hierarchies.Â
- Model-AgnosticÂ
The pipeline can be used with various LLMs, such as Anthropic’s models, OpenAI’s ChatGPT, or Google Gemini. This flexibility enables organizations to adopt or switch LLM providers without losing the benefits of the refinement process.Â
- Increased Robustness
Leveraging ground truth datasets ensures that prompts are evaluated on real-world examples, helping the model handle diverse and ambiguous scenarios with greater reliability.Â
- Meta-Prompt BenefitsÂ
Meta-prompts provide an efficient mechanism to leverage LLM capabilities for self-improvement. By incorporating LLM-generated suggestions, the system continuously evolves in response to new challenges or requirements.Â
- Error AnalysisÂ
The feedback loop enables a focused analysis of misclassifications, guiding the creation of targeted prompts that address specific failure cases or edge conditions.Â
Iterative Workflow for Prompt Refinement PipelineÂ
Baseline Testing – Start with an initial prompt and evaluate it on the ground truth dataset. Log performance metrics.Â
Meta-Prompt Refinement – Use a meta-prompt to generate improved versions of the initial prompt. Select the most promising refinement.Â
Validation and Comparison – Test the refined prompt on the dataset, comparing results to the baseline. Identify improvements and areas where performance remains suboptimal.Â
Targeted Refinements – For consistently misclassified samples, manually analyze and refine the prompt further. Re-evaluate until significant performance gains are achieved.Â
Deployment and Monitoring- Deploy the improved prompt into production and monitor real-world performance. Incorporate newly encountered edge cases into subsequent iterations of the refinement pipeline.Â
A prompt refinement pipeline provides a robust framework for systematically improving the performance of LLMs in hierarchical multiclass classification tasks. By combining meta-prompts, ground truth datasets, and automated evaluation, this approach ensures continuous improvement, scalability, and adaptability to new challenges, resulting in a more reliable and efficient classification system.Â
ReferencesÂ
- For further reading on MTC-LLM, the following papers and blogs provide valuable insightsÂ
- Brown, T. B., et al. (2020). “Language Models are Few-Shot Learners.†*NeurIPS*Â
- OpenAI. “Best Practices for Prompt Engineering with GPT-4.â€Â
- Anthropic. “Building Reliable Classification with Claude.â€Â
- https://www.vellum.ai/llm-parameters-guideÂ
Source: Read MoreÂ
