




The routing mechanism of MoE models evokes a great privacy challenge. Optimize LLM large language model performance by selectively activating only a fraction of its total parameters while making it highly susceptible to adversarial data extraction through routing-dependent interactions. This risk, most obviously present with the ECR mechanism, would let an attacker siphon out user inputs by putting their crafted queries in the same processing batch as the targeted input. The MoE Tiebreak Leakage Attack exploits such architectural properties, revealing a deep flaw in the privacy design, which, therefore, must be addressed when such MoE models become generally deployed for real-time applications requiring both efficiency and security in the use of data.
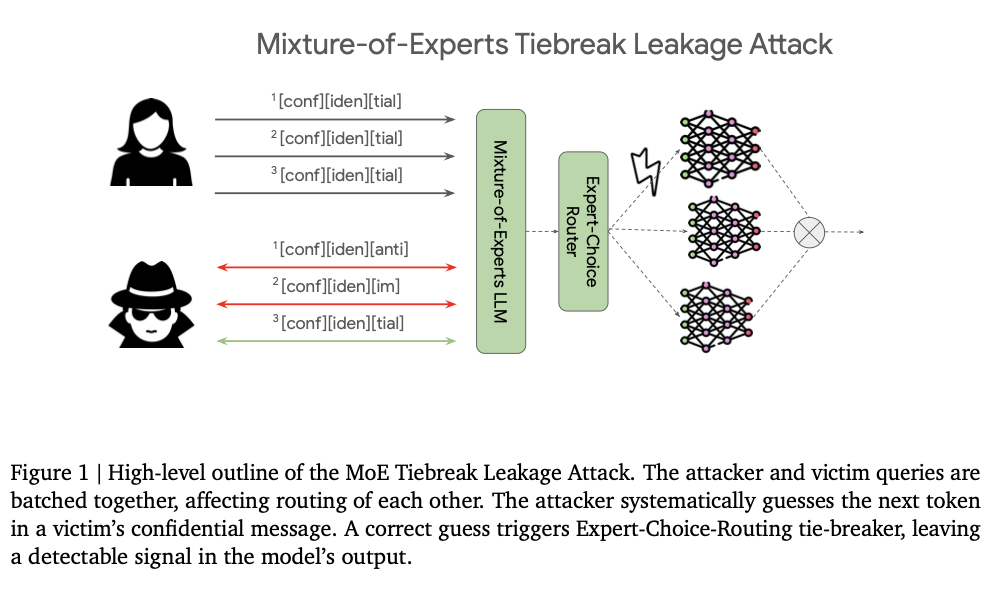
Current MoE models employ gating and selective routing of tokens to improve efficiency by distributing processing across multiple “experts,†thus reducing computational demand compared to dense LLMs. However, such selective activation introduces vulnerabilities because its batch-dependent routing decisions render the models susceptible to information leakage. The main problem with the routing strategies is that they treat tokens deterministically, failing to guarantee independence between batches. This batch dependency enables adversaries to exploit the routing logic, gain access to private inputs, and expose a fundamental security flaw in models optimized for computational efficiency at the expense of privacy.
Google DeepMind Researchers address these vulnerabilities with the MoE Tiebreak Leakage Attack, a systematic method that manipulates MoE routing behavior to infer user prompts. This attack approach inserts crafted inputs coupled with a victim’s prompt that exploits the deterministic behavior of the model in terms of tie-breaking, wherein an observable change in output is observed when the guess is correct, thus making prompt tokens leak. Three fundamental components comprise this attack process: (1) token guessing, in which an attacker probes possible prompt tokens; (2) expert buffer manipulation, through which padding sequences are utilized for control of routing behavior; and (3) routing path recovery to check the correctness of guesses from variations in output differences in various batch orders. This reveals a previously unexamined side-channel attack vector of MoE architectures and requires privacy-centered considerations during the optimization of models.
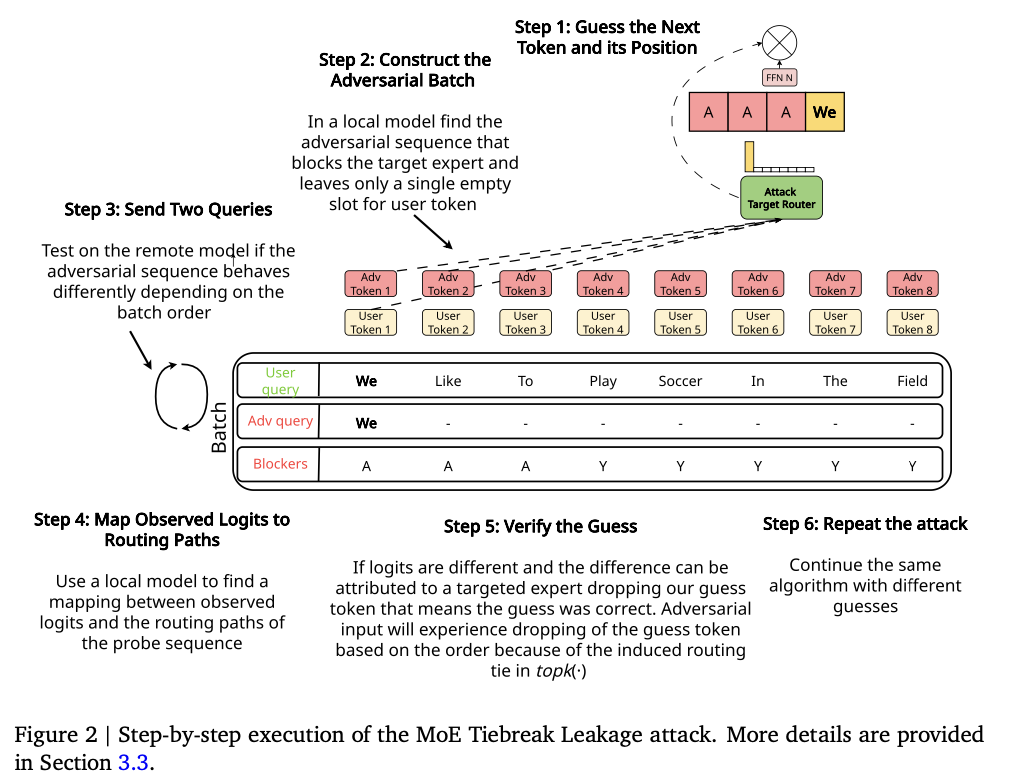
The MoE Tiebreak Leakage Attack is experimented on an eight-expert Mixtral model with ECR-based routing, using the PyTorch CUDA top-k implementation. The technique decreases the vocabulary set and handcrafts padding sequences in a way that affects the capacities of the experts without making the routing unpredictable. Some of the most critical technical steps are as follows:
- Token Probing and Verification: It made use of an iterative token-guessing mechanism where the attacker’s guesses are aligned with the victim’s prompt by observing differences in routing, which indicate a correct guess.
- Control of Expert Capacity: The researchers employed padding sequences to control the capacity of the expert buffer. This was done so that specific tokens were routed to the intended experts.
- Â Path Analysis and Output Mapping: Using a local model that compares the outputs of two batches adversarially configured, routing paths were identified with token behavior mapped for every probe input to verify that extractions are successful.
Evaluation was performed on different length messages and token configurations with very high accuracy in recovering token and scalable approach for detecting privacy vulnerabilities in routing dependant architectures.
The MoE Tiebreak Leakage Attack was surprisingly effective: it recovered 4,833 of 4,838 tokens, with an accuracy rate surpassing 99.9%. The results were consistent across configurations, with strategic padding and precise routing controls that facilitated near-complete prompt extraction. Utilizing local model queries for the most interactions, the attack optimizes efficiency without heavily depending on target model queries to significantly improve the real-world practicality of applications and establish the scalability of the approach for various MoE configurations and settings.

This work identifies a critical privacy vulnerability within MoE models by leveraging the potential for batch-dependent routing in ECR-based architectures to be used to extract adversarial data. Systematic recovery of sensitive user prompts through the deterministic routing behavior enabled by the MoE Tiebreak Leakage Attack shows a need for secure design within protocols for routing. Future model optimizations should take into account possible privacy risks, such as those that may be introduced via randomness or enforcing batch independence in routing, to diminish these vulnerabilities. This work stresses the importance of incorporating security assessments in architectural decisions for MoE models, especially when real-world applications increasingly rely on LLMs to handle sensitive information.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post A New Google DeepMind Research Reveals a New Kind of Vulnerability that Could Leak User Prompts in MoE Model appeared first on MarkTechPost.
Source: Read MoreÂ
